tags:
- OS
- Memory Management
第零课 南大ICS先导课
操作系统的诞生源于人们为了更有效的操作裸机(硬件)和对操作高层次抽象的追求。为了更好的理解本阶段的内容,内存管理阶段开始前,我们需要先了解一点组成原理和体系结构的内容。
0.1 Organization of Memory
我们知道,冯诺依曼计算机是以存储器为中心的。不管是我们的操作系统还是应用都要跑在主存上。那内存和外存的关系是怎么样的?在我们执行某些程序时,程序和数据会从外存批量传送到内存上,在由 CPU 从内存中取指执行。CPU 执行完毕后结果写回到内存中,必要时再由内存成批传送到外存长久保存。

下图展示了主存的结构,我们假设系统按字节连续编址,那么每个存储单元就是一个字节。不难理解,地址线的条数和主存的最大字节数关系就等于:
0.2 Memory Hierarchy
早期人工操作计算机的过程繁琐而复杂。为了简化操作并提高效率,操作系统诞生了,操作系统为人们提供一个”虚拟的机器“,人们再也不用和底层电路打交道。但对于程序员,使用这样的计算机仍不知足,因为内存的发展和 CPU 的相比太慢了。程序员想要的是一种和 CPU 速度相匹配,容量 ”无限大“的存储器。存储器层次结构的思想就是处于这种情况下诞生的。
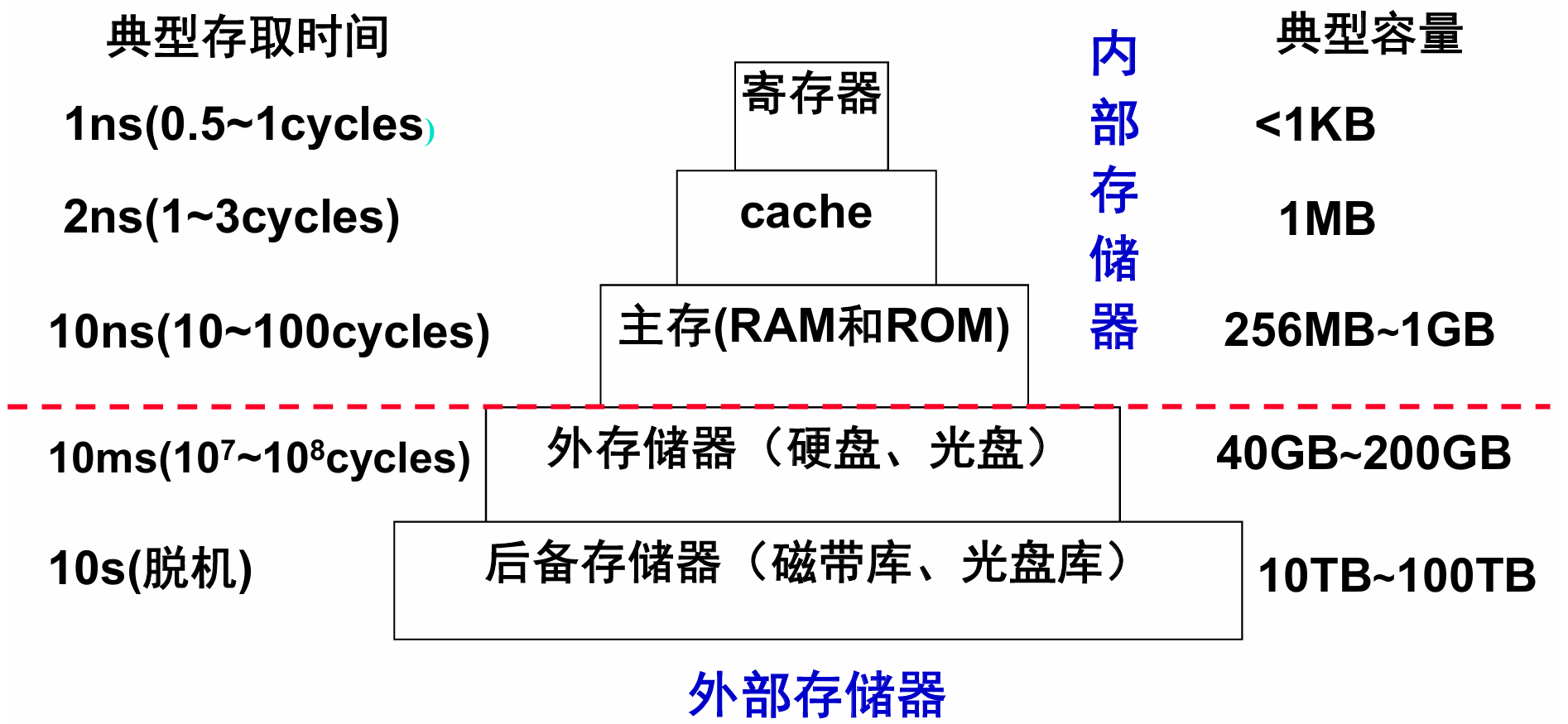
在存储器的层次结构中,只有寄存器和cache能够与 CPU 的速度相匹配,但败在容量小。主存相比 CPU 要慢上10多倍,容量相比cache可以大很多。辅助存储器更是能够提供几近无限的存储大小,但对于 CPU 而言太慢(
这样层次化的存储器结构中,相邻两个层次之间是一定要进行数据传送的。传送的最小单位是一个定长块 (block),互为副本。在主存和磁盘之间,这种定长块被称为页 (page)。在cache和主存之间,就叫定长块(32/64/128字节),cache中最小传送单位叫槽 (slot),定长块大小和槽大小相同。
0.3 Virtual Memory
0.3.1 Memory Management in Early Time
早期的操作系统并不提供内存管理机制。主存空间是需要程序员自己管理的,如果主存空间很小,每次只能在内存中运行一个程序,要运行另一个程序时就需要将上一个进程从内存中取出来,换到外存中先放着,再将外存中需要运行的进程加载到内存中。
在1961年,曼彻斯特的研究人员提出一种自动执行(overlay)的方式,其思想是将地址空间和主存容量的概念区分开。程序员在虚拟地址空间中编写程序,而程序在真正的内存中运行。由一个专门的机制实现地址空间和实际主存之间的映射。
在当时的一种典型计算机中,指令中主存地址是16位,但是主存容量只有4KB。地址空间有
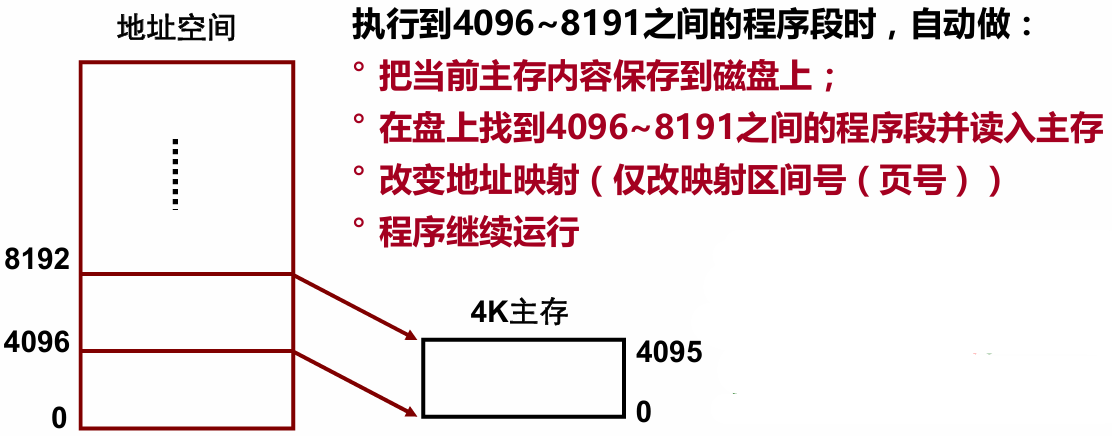
这种可寻址的地址就是一种虚拟内存,区间后来也叫做页(page),把主存中存放页的区域叫做页框(frame)。最早的主存只有一个页框。
0.3.2 Paging Management
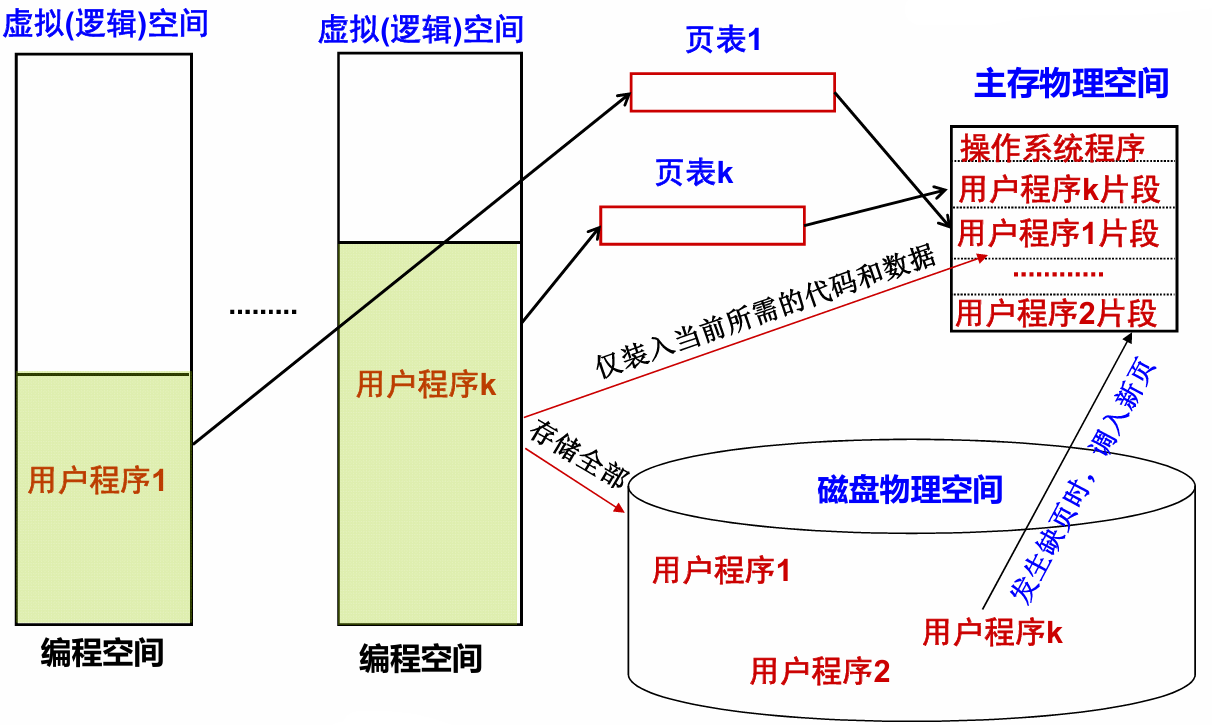
现代的分页方式和早期分页方式十分类似。其基本思想都是把内存分成固定长度的存储块(也叫页框、实页、物理页),每个进程也划分成固定长的程序块(又称为页,虚页、逻辑页)。
在执行程序时,我们就可以把程序块装到可用的存储块中,不需要用连续页框存放一个进程。为此,操作系统会为每个进程分配一个页表(page table)。通过页表就可以实现逻辑地址向物理地址的转换(Address Mapping)。我们下面举例说明一下地址转换:

假如某个进程有四个页的大小。因为虚拟内存中的页和主存中的页框是一样大的,因此我们只需要在页表中描述虚拟页和物理页框之间的映射关系就行了。而且由于程序的局部性,只将活跃的页面留在主存并不会太多影响运行速度。这种”按需调页(Demand Paging)“方式分配主存就是虚拟存储管理的概念。
0.3.3 Virtual Memory and Virtual Space
人们引入虚拟存储技术是为了解决一对矛盾:
- 由于技术成本等原因限制的主存容量;
- 程序要求的主存容量越来越大。
有了虚拟内存,上面的矛盾迎刃而解。程序员可以在比主存大得多的空间内编写程序。当程序执行起来时,只把当前需要的程序段和相应数据块调入主存,不用的地方先放在磁盘上。只当发生缺页(page fault) 时,操作系统才需要介入并进行主存和磁盘之间的信息交换。
虚拟存储器的机制由硬件和操作系统共同协作实现,涉及到操作系统中许多概念,如进程、上下文切换、存储器分配、虚拟地址空间和缺页处理等等。
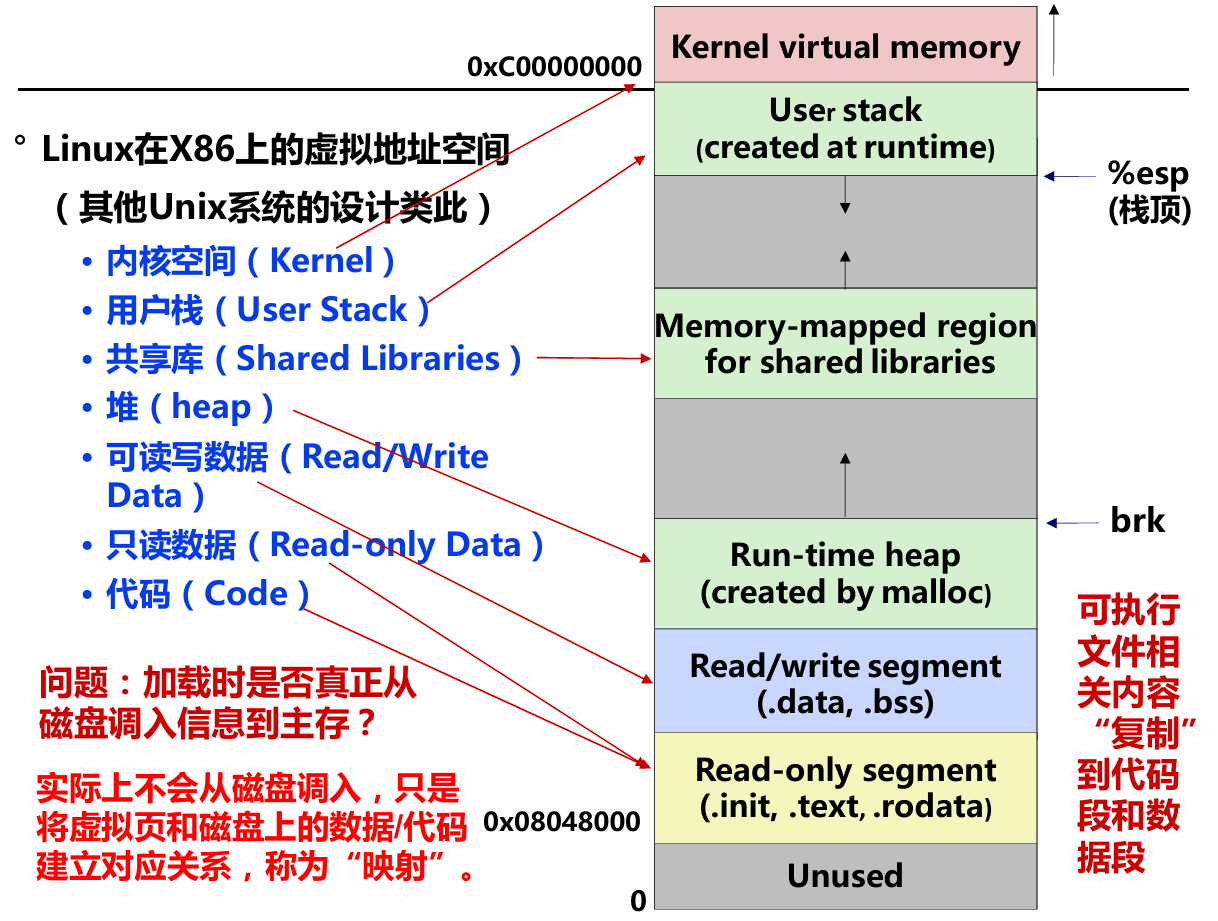
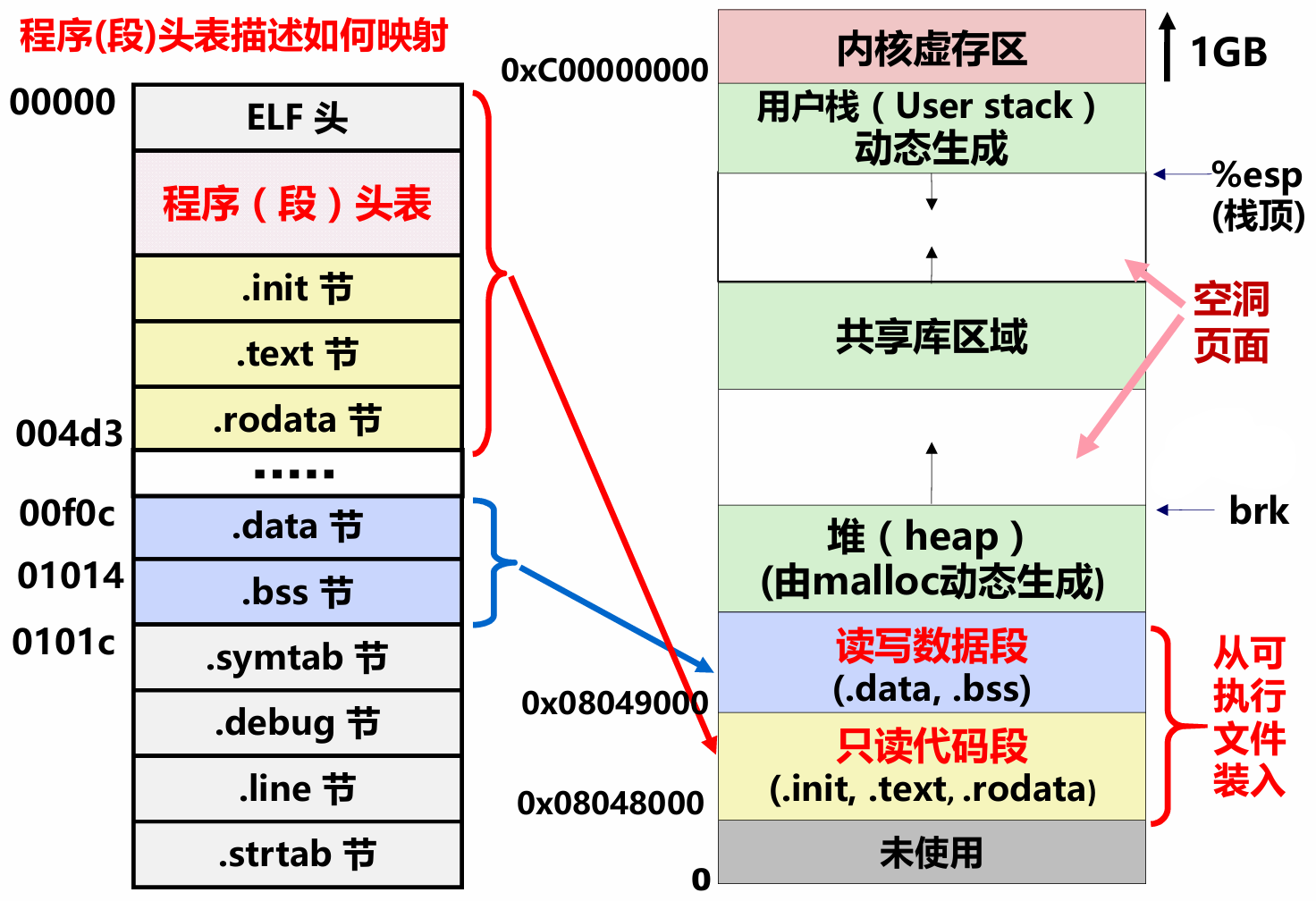
在之前的学习中,我们学习了虚拟地址空间的概念。在32位机器中,每个进程都可以分配高达4GB的虚拟地址空间,不同的操作系统对用户空间和内核空间的大小有不同的规定。我们也可能会有疑问:如果每个进程都在磁盘中占4GB的虚拟空间,磁盘岂不是只能存放很少数量的用户程序?实际上当然不是这样!虽然每个进程都会分配4GB的虚拟内存空间,实际上在磁盘上每个进程可能只会用到很小的磁盘存储(空洞页面不占用磁盘)。
0.3.4 Paging Management Implementation
我们想要实现虚拟存储器的管理,我们还要考虑:
- 页大小应该为多大?
- 主存与辅存的空间如何分区管理?
- 程序块/存储块之间如和映像?
- 逻辑地址和物理地址如何转换,转换速度怎么提高?
- 主存和辅存之间如何进行替换?
- 页表如何实现,页表项要记录那些信息?
- 如何加快访问页表的速度?
- 要找的内容不在主存怎么办?
- 如何保护进程各自的存储区不被其他进程访问?
虚拟存储器的管理分为了三种方式:分页式、分段式、段页式。
假定一个页有4KB,在32位机器上,页表的项数就会有:
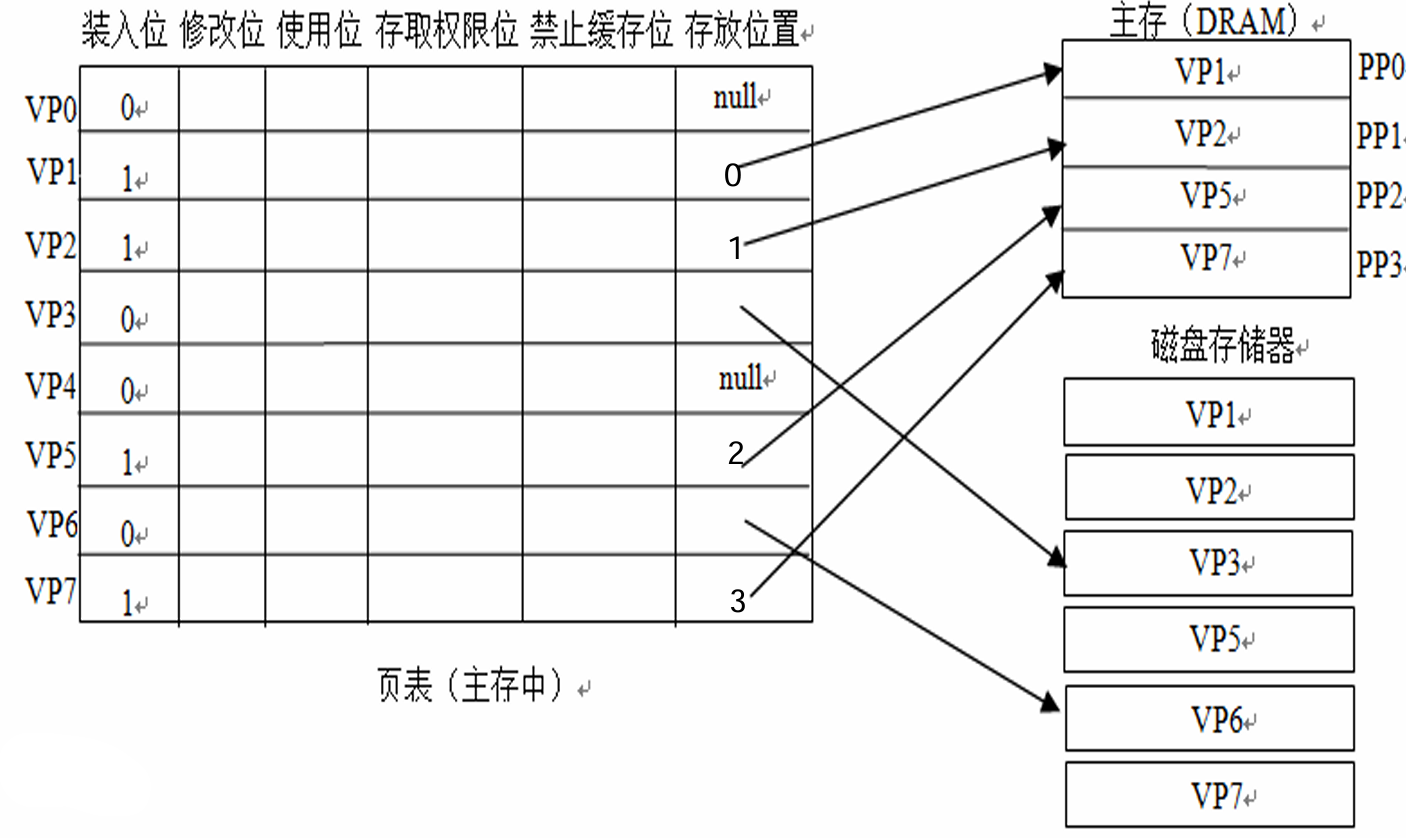
我们将页分成了三类:
- 未分配页:进程的虚拟地址空间中“空洞”对应的页(如VP0、VP4)
- 已分配的缓存页:有内容对应的已装入主存的页(如VP1、VP2、VP5等)
- 已分配的未缓存页:有内容对应但未装入主存的页(如VP3、VP6)
可执行文件的存储器映像如下图所示。
0.3.5 Segmentation
我们已经了解了分页式虚拟存储器是怎么工作的。将虚拟存储空间划分成大小相等的一个个页,然后将主存空间划分成和页大小相同的一个个页框。然后用页表中的页表项对应每个页到页框的关系。但分页的方式会有一些问题,比如一个数据跨在两个不同的页中。
将虚拟地址空间分段很好的解决了这种问题。通过程序数据的需求分配不同的段,按照程序逻辑结构将虚拟地址空间划分成多个相对独立的部分(代码段、只读数据段、课读写数据段等等)。而且相比分页,分段方式能更好地进行存储保护(数据和代码在同一个页中,地址越界、保护违例)。
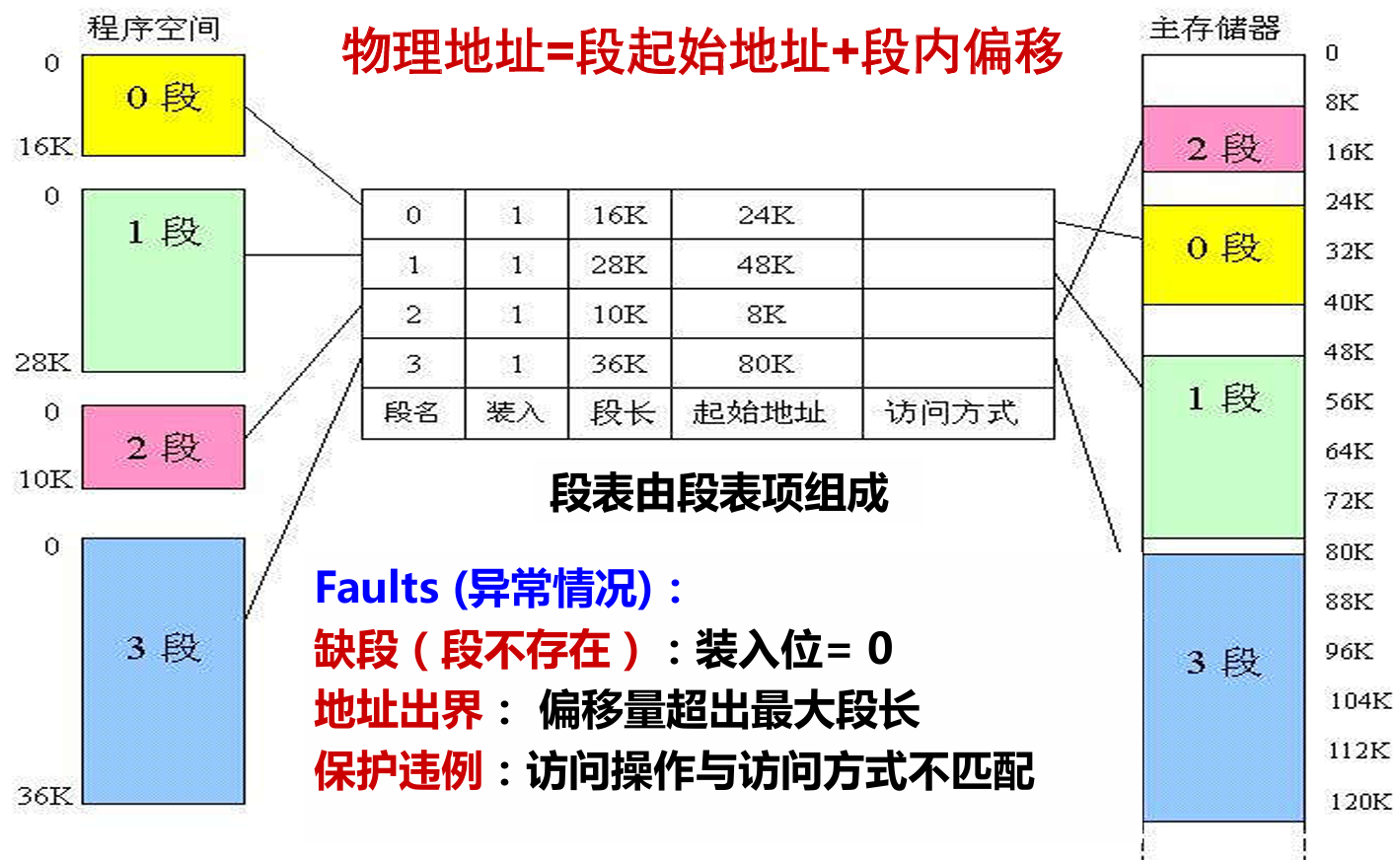
编译器优化和操作系统调度管理。分段系统将主存空间按实际程序中的段来划分,每个段在主存中的位置记录在段表中,并附以“段长”项。段表由段表项组成,段表本身也是主存中的一个可再定位段。
0.3.6 Segmented Paging Management
分段式的虚拟内存管理确确实实解决了分页式虚拟内存管理的痛点,但是它也走向了另一个极端。占空间多,段内存换进换出很难管理。因此我们折中,段页式存储器完美的迎合了我们的需求。
程序的虚拟地址空间按模块先分段、段内再分页,但进入主存仍以页为基本单位。这一,逻辑地址就由段地址+段内页地址+页内偏移量三个字段构成。用段表和页表(每段一个)进行两级定位管理。根据段地址到段表中查阅与该段相应的页表首地址,转向页表,然后根据页地址从页表中查到该页在主存中的页框地址,由此再访问到页内某数据。
第一课 Main Memory Management
在第零课的学习后,我们应该对虚拟内存有了大概的理解。在操作系统中,内存管理涉及的是“内存-外存”这个层次的管理。外存(如磁盘)作为一个大仓库,为用户进程提供逻辑上无限大的编程空间。由于磁盘是一种外部设备,我们将这种磁盘提供的后备资源称为虚拟内存。因为这种逻辑上的关系,也被称为逻辑内存。在本阶段,我们需要额外关注以下的话题:
- 内存的物理地址和进程的逻辑地址
- 地址映射和内存保护
- 内存分配和回收
- 分页和分段
- 虚拟内存
1.1 Physical Address and Logical Address
当我们使用内存时,感受到的是一段连续的内存,这多亏了操作系统的抽象。而我们实际上使用的内存在物理上的地址可能并不连续。我们下面先来了解什么是物理内存地址,它是怎么得到的?
1.1.1 Main Memory
我们直接访问的数据无一例外都存放在主存中。由于主存采用随机存取方式,因此也称为随机存取存储器(Random Access Memory, RAM)。它是计算机系统中的关键硬件组件,用于临时存储和快速访问数据和指令。
下面是RAM的一个组织图,每个bit数据存放在内存中一个个cell中。计算机通过字线和位线将这些cell编址成一个位平面(Bit plane)。由于大多机器按字节编址,所以一般的DRAM bank需要8个这样的位平面摞在一起。下图的例子并不确切,但对于理解地址译码来说是一个很好的例子。

物理地址和地址译码的关系很紧密。假设上图我们有8个位平面,我们可以通过物理地址来得到我们想要的byte。其中,我们就需要一个译码器将物理地址翻译成某个确切的byte信息。
地址译码器有n个地址输入线和
1.1.2 Physical Address
物理地址是计算机内存中的实际地址。每个内存单元都有唯一的物理地址,通过这个地址,CPU可以直接访问内存中的数据。物理地址是由硬件直接管理的,因为它在硬件层面上是唯一且固定的,因此也被称为绝对地址(absolute address)。
物理地址一般从0开始,而且一般以字节作为最小单位。至于物理地址的长度多大要取决于CPU的架构。32位架构就能访问4GB大小的物理内存。64位架构能访问的大小则是一个天文数字,有生之年也不知道能不能见到这么大的存储器。
1.1.3 Logical Address
在第零课的先导课中,我们提到了段页式虚拟内存管理。逻辑地址就等于段基址+偏移量(相对地址)实现的。这里的相对地址就是相对段基址而言的。将地址从一种形式(如逻辑地址)转换成另一种形式(如物理地址)的过程。在现代计算机中,一般使用MMU来完成地址转换的工作。
在用户眼中连续的地址就是逻辑地址。逻辑地址是程序运行时CPU生成的,操作系统分配给进程使用的地址。每个进程都有各自的逻辑地址,通常从0开始。
1.1.3.1 Relative Address
物理地址 = 绝对地址,但逻辑地址 != 相对地址。相对地址是相对于某个基准地址来说的。由编译器在编译时生成,通常用于指令中的跳转、调用等。也就是偏移量(offset)。
第二课 Address Conversion
2.1 How Program is Loaded
在我们用c程序编写了一个hello.c文件后,计算机是不能直接执行这个文件的。原因是计算机只能识别二进制的机器级代码,hello.c是源程序的文本文件。要让计算机识别并执行我们所编写的源程序,还需要做以下步骤:
- 预处理(cpp)
预处理阶段,程序会处理以 '#' 开头的预编译指令并删除所有的代码注释。经过预编译的处理,我们得到预处理文件(hello.i),这时的文件仍然是一个可读的文本文件,不包含任何宏定义。 - 编译(cc1)
编译过程就是将预处理后得到的预处理文件(如hello.i)进行 词法分析、语法分析、语义分析、优化后,生成汇编代码文件。经过编译后,得到的汇编代码文件(如hello.s)还是可读的文本文件,CPU无法理解和执行它。 - 汇编(as)
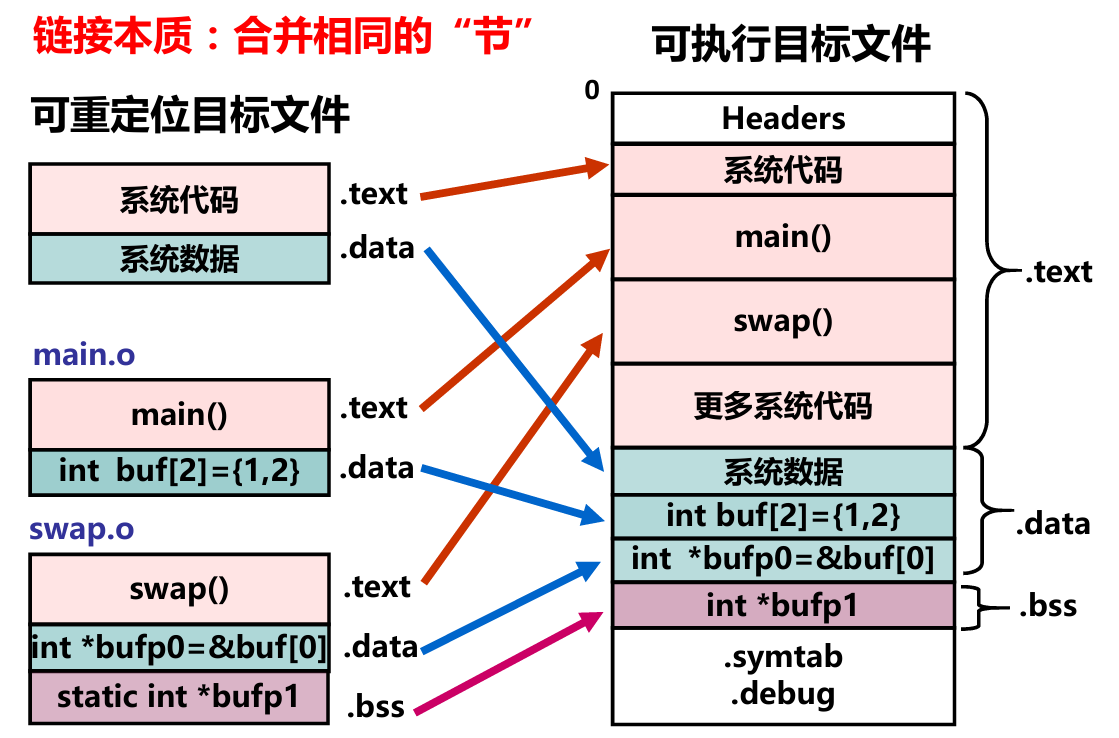
程序经过编译后生成汇编语言源程序,在汇编阶段,汇编程序(汇编器)会用来将汇编语言源程序转换成机器指令序列(机器语言程序)。汇编指令和机器指令一一对应,前者是后者的符号表示,它们都属于机器级指令,所构成的程序称为机器级代码。汇编结果是一个可重定位目标文件(如,hello.o)。 - 链接(ld)
链接过程将多个可重定位目标文件合并以生成可执行目标文件。
- 装入内存
2.1.1 Assembly Code Example
因为汇编代码和二进制机器代码都是机器级代码,因此我们能很明白地在汇编代码中,窥见一些程序加载前的要做的事。代码中CALL和PRINT两个标号代表了那一行指令的逻辑地址,这些标号会在链接过程中经过符号解析和重定位转换成相应的逻辑地址。而这些逻辑地址会在不同时机 中将逻辑地址转换成不同的物理地址。
Logical address Assembly code
0000 START: MOV AX, 1234H
0003 ADD AX, 5678H
0006 JMP NEXT
0009 HERE: SUB AX, 1234H
000C NEXT: MOV BX, AX
000F CALL PRINT
0012 HLT
0013 PRINT: PUSH AX
0014 POP AX
0015 RET
2.2 When does Address Conversion Happen?
2.2.1 Link-Time Conversion
源代码被编译成目标文件,生成的目标文件包含逻辑地址,逻辑地址从0x000开始。在链接阶段,决定程序将被加载到物理内存中的确切位置。之后链接器会将目标文件中的所有逻辑地址转换位相对于加载地址的物理地址。例如,假设决定程序将加载到物理位置0x300,随后,0x300就变成一个基地址,虚拟地址0x003就会被转换为物理地址0x303。
这种链接时地址转换的好处就是简单,而且系统开销低。但是缺点也是显而易见的,那就是灵活性差,不适合多任务的环境。只用场景只有哪些简单的单任务系统。
2.2.2 Load-Time Conversion
链接时转换的方案是在可执行文件加载进内存前就已经指定好在物理内存的哪个位置运行了。装载时转换指在可执行文件被加载到内存时,将程序中的逻辑地址转换成物理地址的过程。这种方法在程序加载时进程一次性转换,并将地址固定下来,也称为静态重定位。适用于内核模块和动态链接库(DLL)等场景。
相比链接时转换,加载时转换的方式更为灵活,因为程序的逻辑地址在编译和链接时不需要是固定的,可以在加载时根据内存的实际情况进行调整。但是这种方式不可避免的导致加载时间增加,而且加载后不可在内存中移动。
2.2.3 Run-time Conversion
加载进内存程序中的指令地址仍然保存逻辑地址,在执行过程中,将逻辑地址动态转换成物理地址。这个过程就是运行时地址转换,也叫动态重定位。动态重定位通常通过硬件和操作系统的支持,比如使用 MMU 实现逻辑地址到物理地址的映射。运行时转换是现代系统中广泛采用的方法。
- 优点:高灵活性、内存保护、高效内存利用。
- 缺点:性能开销大、复杂性高、对硬件要求。
2.2.4 Logic Address to Virtual Address
- 编译阶段:源代码转成目标代码,每个目标文件中的地址称为逻辑地址。
- 链接阶段:将多个目标文件链接合成可执行文件,该阶段会分配每个段的虚拟地址,在根据目标文件的逻辑地址和加载段生成全局虚拟地址。此时虚拟地址空间就构建完毕,构建信息就是ELF的头部信息。
- 加载阶段:OS 会先读取ELF头部信息,根据虚拟地址空间的信息加载必要的段到物理内存中,其他部分留在虚拟内存。
- 运行阶段:当某个要访问的页不再内存中,则请求操作系统从虚拟内存将其调入物理内存。如果物理内存不足就进行页面置换。
第三课 Base and Bound
3.1 Memory Management Unit
内存管理单元(MMU),也叫页内存管理单元(PMMU),是一种支持虚拟内存和分页的硬件设备或电路,负责将虚拟地址转换成物理地址。
- 在现代操作系统中,进程的逻辑地址空间大小理论可达计算机架构的最大值,而物理内存通常比理论最大值小。
- 一个进程通常不会用完全部的逻辑地址空间,也很少会在在某一时刻使用大量内存。因此,可以同时在物理内存中容纳多个进程。
- MMU的任务就是把每个进程的逻辑地址映射到物理内存的不同区域,同时也要保证进程之间的隔离性(保护地址不会越界或溢出)。
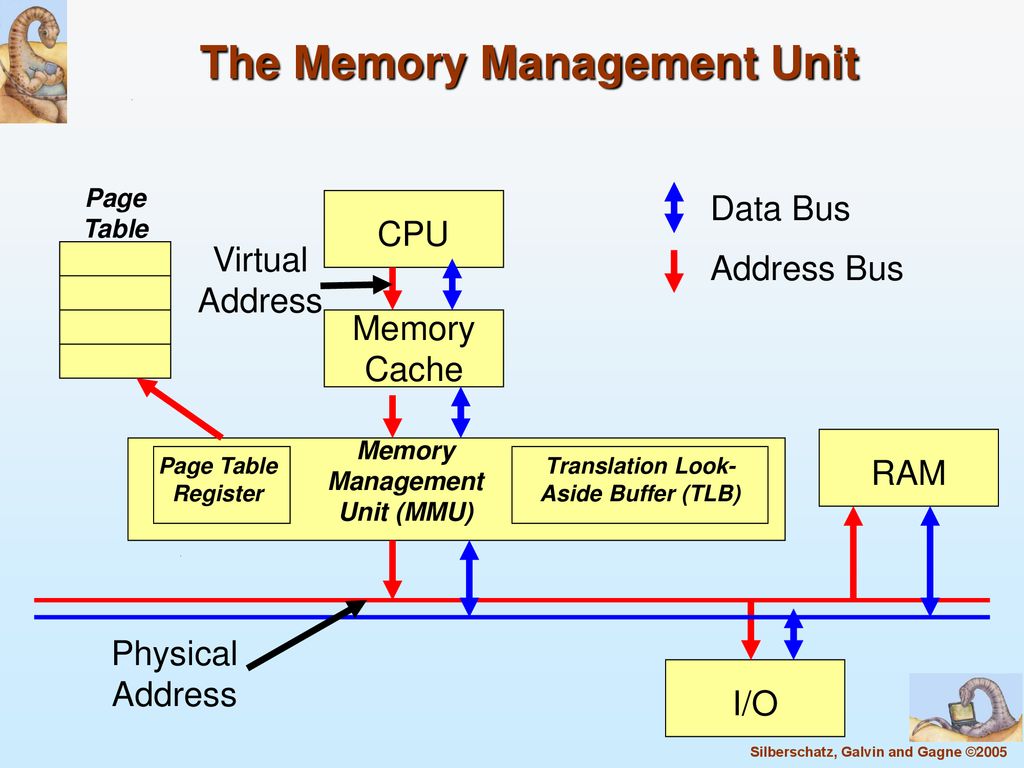
3.1.1 Base and Bound
基址和限长是虚拟内存的一种简单形式,通过一组或少量处理器寄存器(基址寄存器和限长寄存器)来控制对计算机内存的访问。工作原理如下:
- 分配内存区域
每个用户进程被分配一个连续的主存区域。操作系统将该区域的物理首地址加载到基址寄存器(重定位寄存器)中,将其大小加载到限长寄存器中。
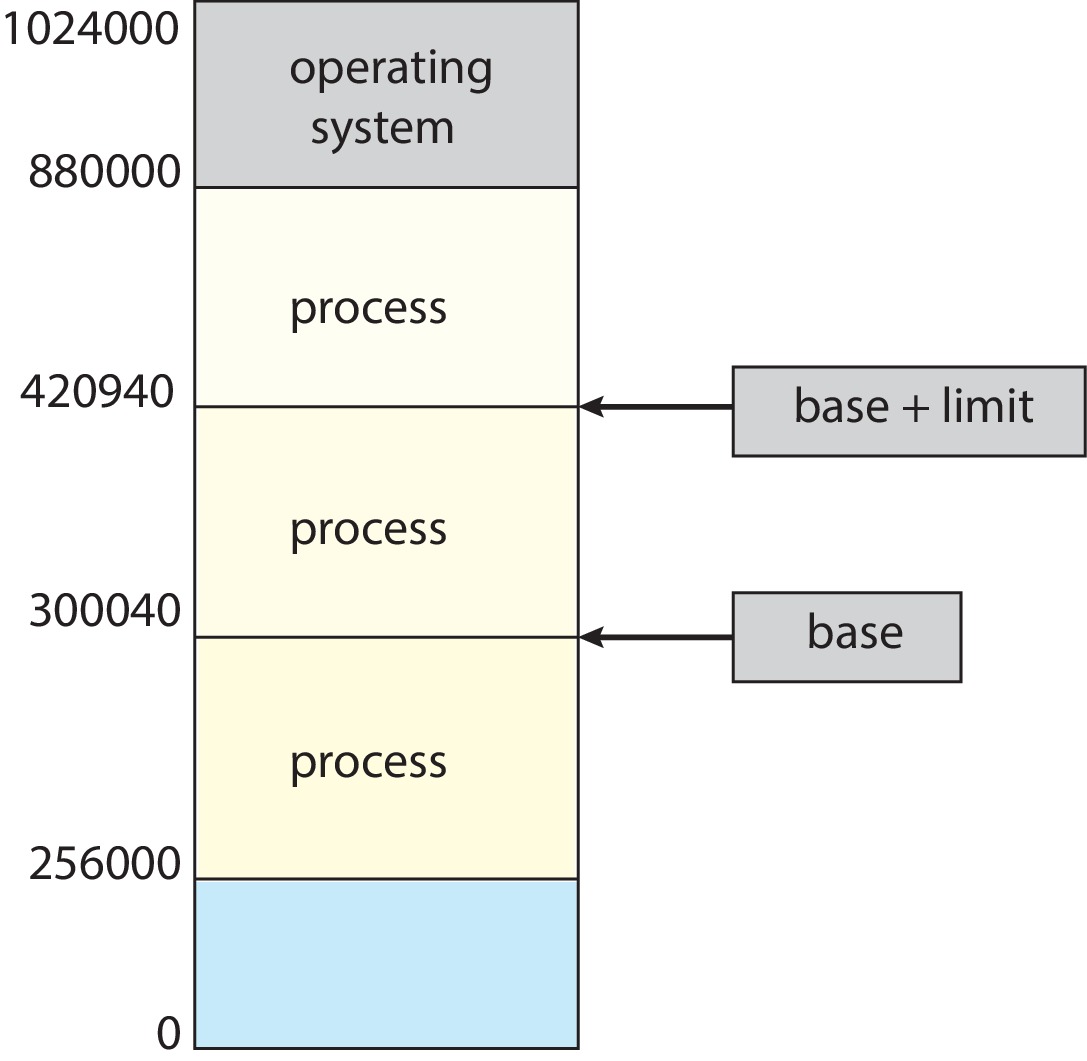
-
物理地址转换
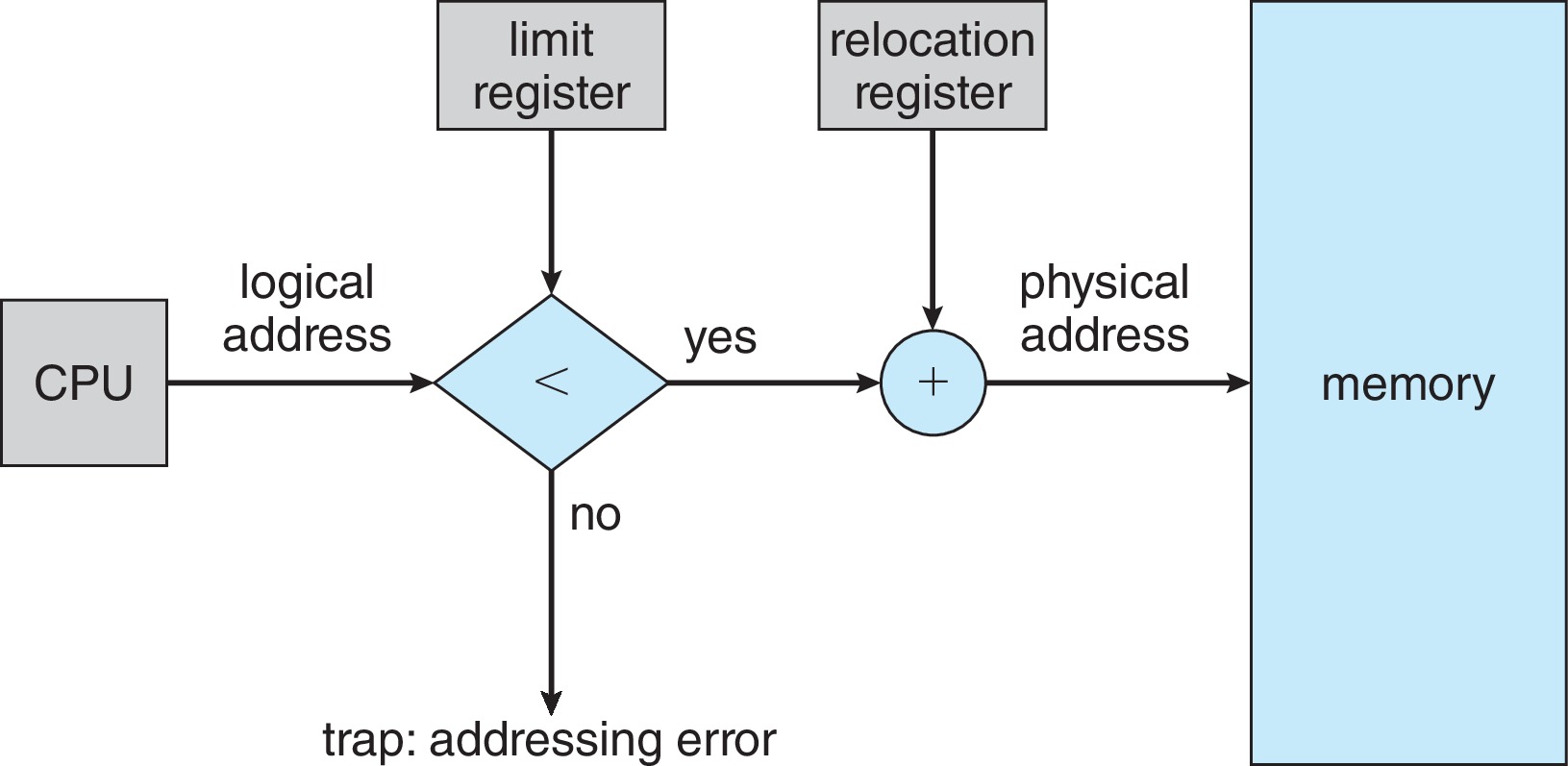
我们已经了解了基址寄存器和编址寄存器的作用,我们通过下图直观学习以下物理地址是这么转换的。当进程重定位到 14000 地址的基址时,这个基址会存放在基址寄存器中,和CPU送来的所及地址相加就可以得出物理地址了。不过要注意,在这里还要判断地址是否越界的问题,我们马上介绍。
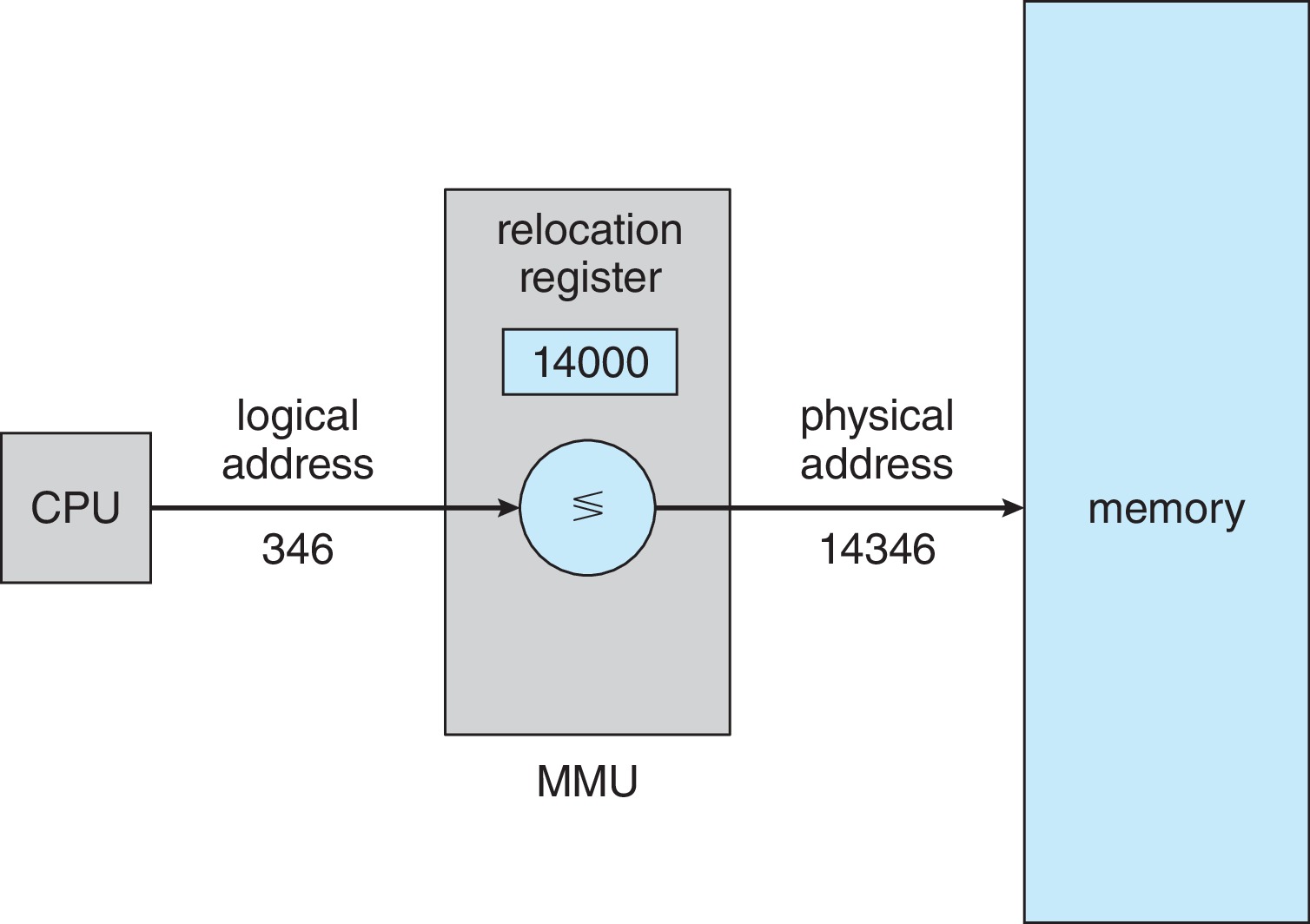
-
内存保护
通过进程P中基址和限长寄存器中的值,我们就可以轻松地判断是否存在非法的址错误。在下图中,硬件(MMU)会检查每个CPU送来的地址,检查是否越界等等。一旦发现送来的地址值小于基地址,或者大于限长寄存器(base+limit)中的值,MMU就会通过一条trap指令叫出操作系统处理这种 addressing error。
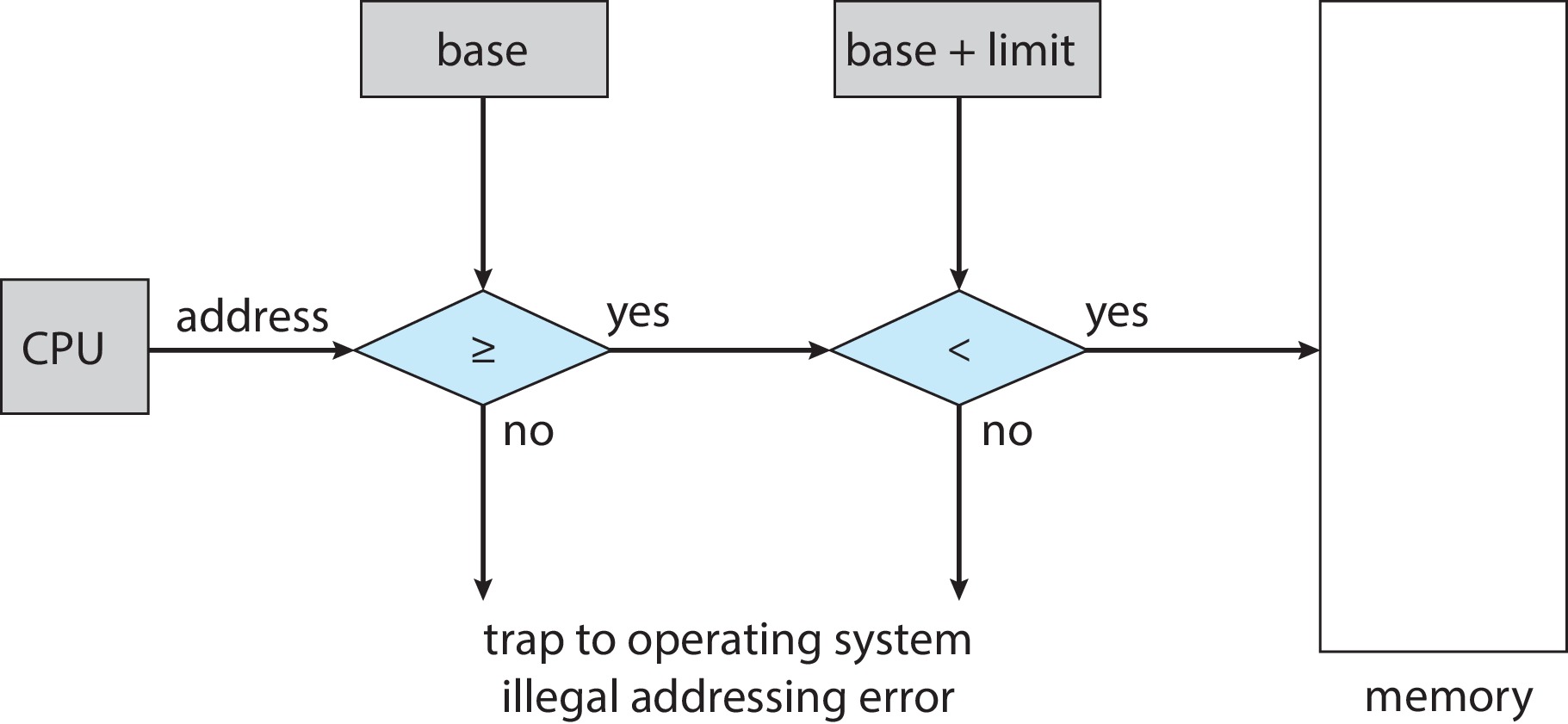
结合物理地址转换和内存保护,我们就可以简单的描述出MMU地址转换和内存保护方法的步骤了。因为CPU送来的是逻辑地址,因此我们在这里省略和基地址的比较过程。
第四课 Contiguous Memory Allocation
在计算机的内存管理中,连续分配管理方式是一种基础的分配方法。它的主要特点是将进程装入内存时,要求进程占据一块连续的内存空间。这种方法可以有效的管理和分配内存资源,但是也会有一些限制。
连续分配管理方式可以进一步细分为固定分区和可变分区两种模式。这两种模式各有优缺点,适用于不同的应用场景。后面的分段、分页就是对这两种模式的延伸。
4.1 Fixed Size Partitioning
固定分区管理方式是一种将内存划分为若干固定大小分区的方法(分区大小不一定相同)。由于内存分区大小固定,所以每个分区在系统启动时就已经确定,不能动态调整。此外,在固定分区中,每个分区只能容纳一个进程,如果一个进程之战1MB,而分区大小为5MB,这就会造成4MB的浪费,即内部碎片(Internal fragmentation)。当我们分配分区时,尽量使得内部碎片尽可能的小。
当系统有多个进程需要运行时,会将每个进程分配到一个合适大小的分区中。如果所有分区都被占用,新到的进程将无法进入内存,必须等待。

4.1.1 Memory Allocation and Deallocation
在固定分区中,为了实现内存的分配和回收,系统需要维护一张表用于跟踪分区当前的状态。这张表记录着各个分区的编号、起始地址、大小和占用情况。
4.1.1.1 Memory Allocation
在固定分区下,当进程需要申请内存空间时,分配器会根据进程的大小,在表中寻找一个合适的分区进行分配。之后,将该分区的起始地址填入 Base register 中,将分区大小或进程大小填入 Limit register 中,并标注占用该分区的进程 ID 号。
4.1.1.2 Memory Deallocation
当进程结束后,清除该分区的占用情况使分区重新可用。
4.1.2 Address Conversion and Protection
在固定分区中的地址转换和保护中有两种不同的声音:
- 限长寄存器中应当存放的是分区大小,也就是物理地址在内部碎片中也是允许的;
- 限长寄存器存放的是进程大小,限制进程在分区内部碎片的访问权限。
4.1.3 Trade-Offs
权衡利弊,固定分区的好处就是简单易实现。但是其不灵活的缺点难免导致产生大量的内存内部碎片,不可避免的造成资源的浪费。
4.2 Variable Size Partitioning
与固定分区的管理方式不同,可变分区的管理方式并不与先划分固定大小的分区,而根据进程的实际需要动态地分配内存。
4.2.1 Memory Allocation and Deallocation
由于可变分区的内存管理方式不再固定地划分分区。为了确保内存分配高效性,系统需要维护两张表:空闲分区表和已用分区表。空闲的分区也叫做孔(holes),初始情况下,整个内存区域就是一个空闲分区。
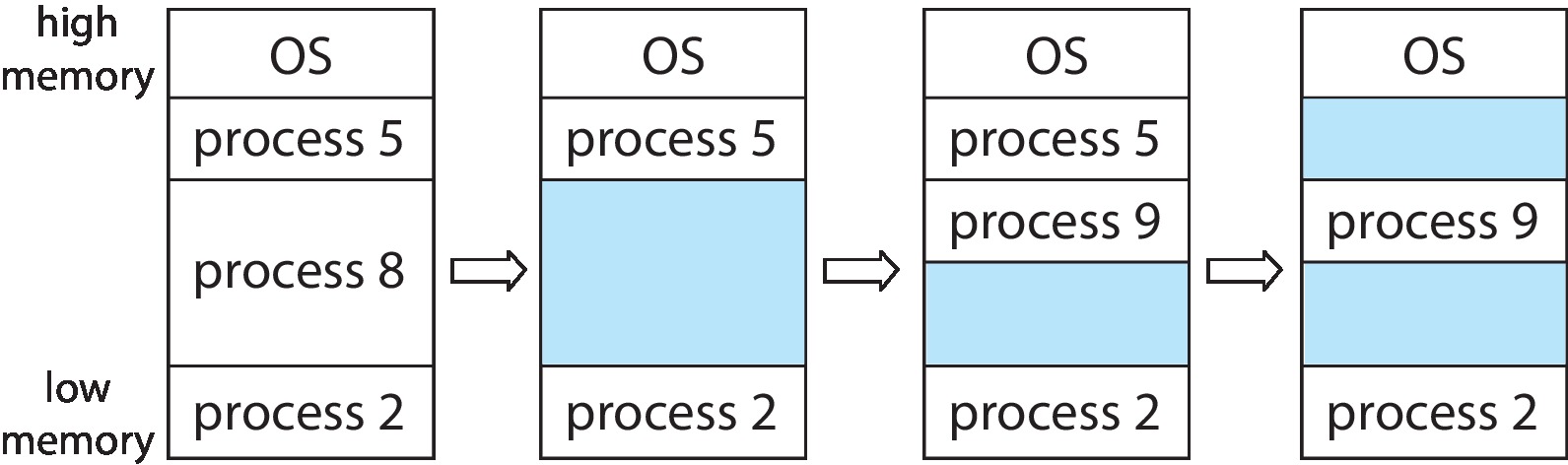
4.2.1.1 Allocation
根据进程大小在空闲分区表中寻找一个合适的分区进行分配,更新空闲分区表和已用分区表,并初始化进程的 Base register 和 Limit register。
4.2.1.2 Deallocation
在释放内存时,更新已用分区表和空闲分区表(如果可以,合并多个连着的空闲分区,这被称为 coalescence)。
4.2.2 Memory Conversion and Protection
没什么好说的,参见上节课内存保护的部分。
4.2.3 Trade-Offs
相比固定分区,可变分区为我们带来了一定的灵活性。由于分区大小就是进程的大小,所以可变分区避免了内部碎片的产生。然而,这种分区为我们带来了外部碎片,也就是我们说的holes。如果孔的分配不合理,就可能出现许多无法利用的孔。
为了减少外部碎片的占比,在可变分区中,我们有许多分配算法。
4.3 Allocation Algorithms
由于可变分区的分区方式是动态可调整的,因此如何分配“孔”就决定了内存的利用率。常见的分区策略有——First fit、Next fit、Best fit、Worst fit、Quick fit。
4.2.3.1 First Fit
首次适应从头开始搜索空闲分区表,检查每个块。一旦找到大小合适的空闲分区块,将其分配给进程。除了这种分配方式可能产生过多的内存碎片外,首次适应有许多优点:
- 速度快 O(n),找到第一个合适的就能分配了。
- 易于实现。
4.2.3.2 Next Fit
下次适应是从上次分配结束的位置开始,继续向前查找,找到第一个足够大的空闲块进行分配。如果到达内存末尾,则从头开始继续查找。下次适应具有与首次适应(First Fit)相同的优点:速度快O(n)和易于实现。
在某些情况下,下次适应可能更均匀地利用内存,因为它不会总是从内存的起始位置开始查找。然而,它也可能会导致更多的内存碎片,因为它不会总是选择最靠前的空闲块。此外,下次适应可能在某些情况下更快,因为它避免了每次分配都从头开始查找。
4.2.3.3 Best Fit
相比于前两种傻瓜式的比较适应算法,最佳适应会搜索整个空闲分区表,找到最接近进程所需大小的空闲分区块,然后将其分配给进程。相比较于前两者,最佳适应的外部碎片产生最小。但是有些实现方式可能使得搜索时间过长。
然而,如果使用 AVL 树或红黑树,最佳适应算法的速度可能会优于首次适应算法:Θ(In(n))。
4.2.3.4 Worst Fit
最差适应算法反其道而行之,它通过搜索整个空闲分区表,找到最大的空闲分区表,将其分配给进程。为什么是最大的内存块?因为大块内存分配后,留下的空闲区域依然很大,便于后续的分配。这就是最差适应的中心思想,但是也可能造成更大的内存浪费。
可以使用 max heap、 binomial heap 或 Fibonacci heap 来实现最差适应算法。
4.2.3.5 Quick Fit
快速适应是一种优化内存分配速度的算法。它通过维护多个空闲块列表,每个列表对应不同大小的内存块。当需要分配内存时,Quick Fit 会直接从对应大小的空闲块列表中查找和分配内存。这种方法可以显著减少内存分配和释放的时间开销,但可能会导致内存碎片问题。
4.2.4 可变分区和空间利用技术
- 可变分区方式的内存利用率较高,可以更灵活地适应不同大小进程的需求。
- 存在外部碎片(孔)和分配开销。
- 合并技术 (coalescence):内存管理器会将相邻的空闲块合并成一个更大的空闲块。
- 紧凑技术 (compaction):将进程在内存中进行移动,消除不可用的孔。但是这种移动内存块的方式会增加系统开销。
4.3 Binary Buddy System
第五课 Segmentation
在上节课的连分配管理方式中,我们看到无论是固定分区还是可变分区,都要求进程在内存中是完整的。但无论是哪种连续分配方式,都不可避免的会有碎片产生。因此,在本节课及往后,我们开始讨论非连续性存储管理方式,为找到一种更好的方式管理我们的内存。
实际上,我们在阶段6第三课中已经对“段”这个概念有所耳闻了。我们知道虚拟内存中不同的段承担的职责是不一样的,我们有代码段、全局变量段、stack、heap、C标准库等各种段。尽管段内地址连续,但不同的段在内存中可以离散排布,我们依据不同的段对内存进行管理。
5.1 Allocation and Deallocation
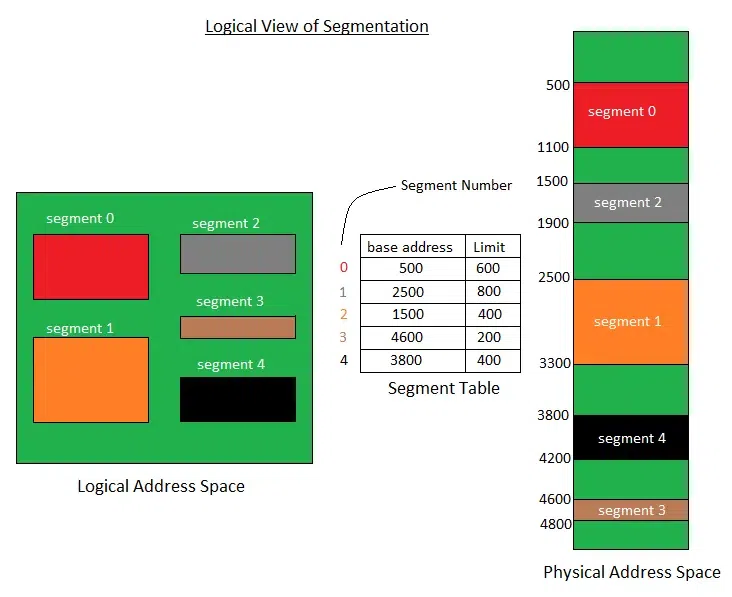
段式存储管理方式中,逻辑空间被分为了若干个段,每个段定义了一组完整逻辑意义的信息(代码段、数据段、堆栈段)。段式存储管理的优点是不同的段在加载进内存时不要求是连续的,但是某一个段内的内存需要是连续的。
- 分段:每个逻辑段都有一个段号。
- 段内连续:段内的逻辑地址总是从 0 开始。
- 段的大小:不同段的大小不完全相同。
- 段表:段表用来记录每个逻辑段的编号。物理起始大小、段大小及访问权限等。
下面举例用段表只展示出内存保护所需的段基址和段长部分。
- 分配方式:读取ELF头部,识别出需要加载的各个段,为每个段分配内存(查找、更新空闲分区表),最后更新段表。
- 回收过程:更新段表->释放内存(更新空闲表)。
5.2 Conversion and Protection
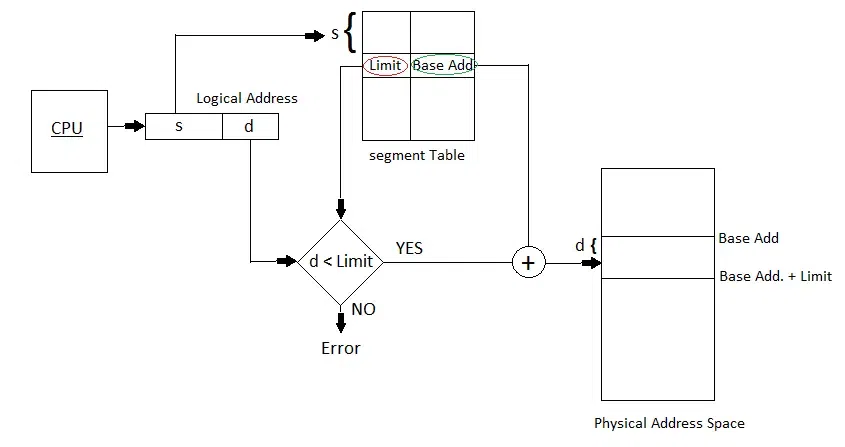
5.2.1 Conversion
逻辑地址由两部分构成:(1)段号,(2)段内偏移。段号决定虚拟内存中可划分多少个段,段内位移决定最小的段大小是多大。
5.2.2 Protection
- 防止越界
- 访问权限(CPL 和 DPL,还有段属性是只读、只写还是怎样)
5.3 Trade-Offs
第六课 Paging
我们在 ICS 先导课中已经学过页式存储的基本原理,我们将进程逻辑地址空间划分成大小相同的块,我们称为页(page);再把物理内存划分成若干相同大小的块,称为页框(page frame)。一个页框放一个页。当我们分配内存时,我们可以将进程的页面离散地存放到也框里面,通过页表保存页和页框的映射关系(虚拟地址到物理地址之间的映射)。
6.1 Page Table
在32位机器上,逻辑地址占32bits,其中有页内位移12bits和页面号20bits。我们知道,页和页框中的页内位移是一一对应的。其中,逻辑地址通过页表映射出相对应的物理地址。因此要实现页式存储管理,页表中的页表项不需要记录页内位移的任何信息。而且虚拟地址空间是连续的,我们只需要在页表项中记录页框号和一些标志位即可。
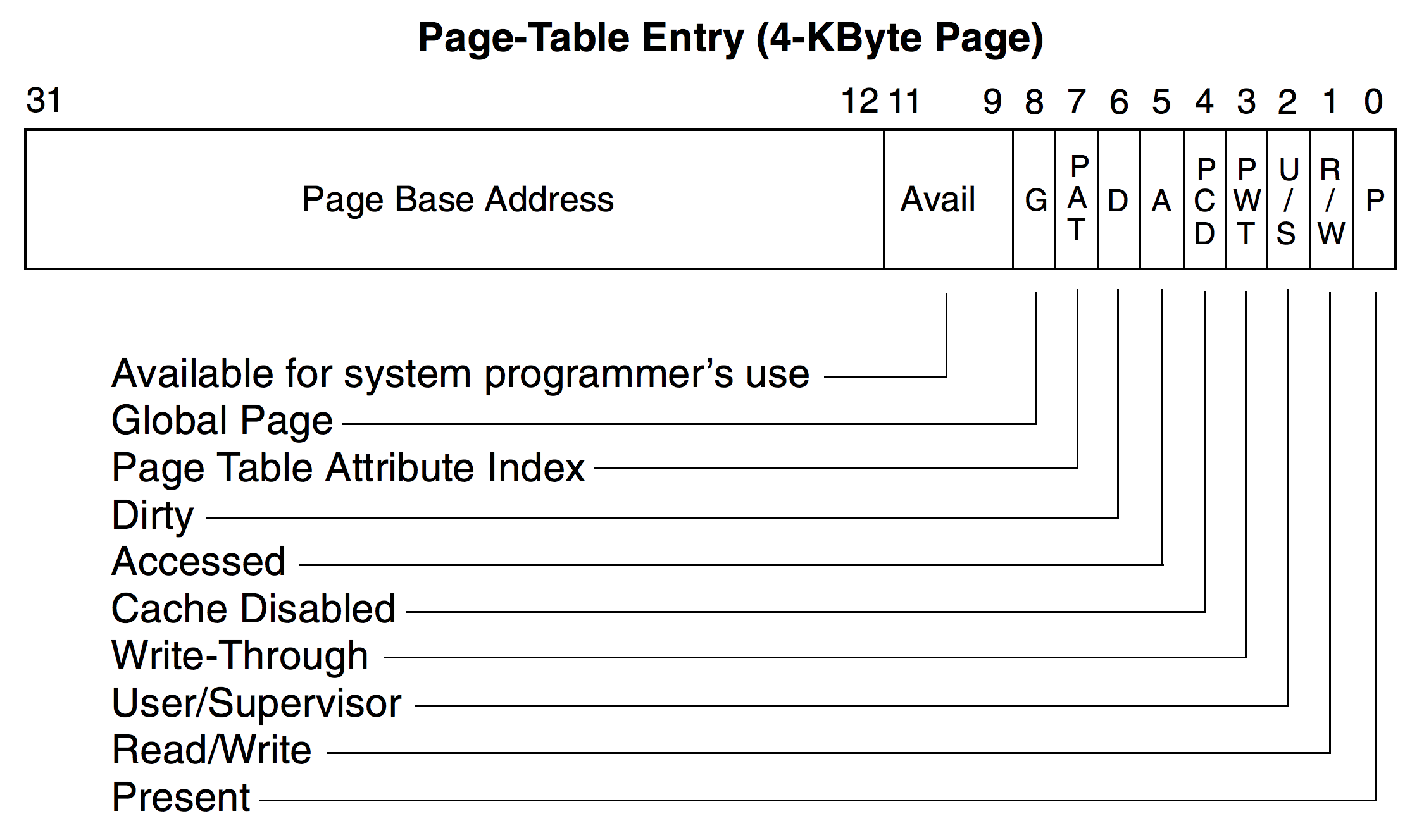
6.1.1 Page Table Entry
32位机器上的页表项占四个字节,这里提供下面的图简单了解相关位的含义。
6.2 页式存储管理方式的开销
6.2.1 页表存储开销
32位机器上,一个进程的虚拟地址空间理论上是 4GB 空间,每个页 4KB 情况下可以划分出来 1M 个页出来。我们知道每个页表项需要 4B 空间,那么维护这一个进程的页表就需要占用 4MB 的内存空间(单级页表静态分配需要1000个连续页框的大小)。为了解决单个进程的页表占用大量内存的问题,通常采用多级页表(Multi-Level Page Table) 方案,我们会在之后的课程中学习。
6.2.2 页表查询开销
当 CPU 想要访问一个逻辑地址时,会触发地址转换,这时需要访问物理内存两次。
- 访问页表:不难理解,你想从虚拟地址得到物理地址,你就需要从PTBR(Page Table Base Register)读取页表起始地址,然后从这个页表中查询页面号对应的页框号。随后得到物理地址。
- 访问转换后的物理地址
当 CPU 频繁访问内存时,页表查找的开销会显著增加。这时,我们采用一种更高效的解决方案——快表。我们将在下节课介绍。
6.3 页的分配和回收
- 分配过程
- 读取ELF头部,识别出需要加载的各个段
- 为每个段的虚拟地址划分页面
- 为每个页面分配一个页框(查找并更新页框表)
- 更新页表
- 回收过程
- 更新页表
- 释放内存(更新空闲页框表)
6.4 地址转换和保护
6.4.1 地址转换
在虚拟地址空间中,我们把虚拟的地址空间划分成一个一个页,因而产生的逻辑地址很容易得出来:虚拟地址 = 页面号 + 页内位移。

6.4.2 内存保护
页表项处理页框外,还有很多标志位来提供更为精细的访问控制。
- P(Present)位:表示页是否在物理内存中(1表示页在内存中)
- R/W(Read/Write)位:控制页的读写权限(0表示可读/1表示可读写)
- U/S(User/Supervisor)位:控制页的访问权限(0表示只有内核能访问/1表示用户也可以访问)
- A(Accessed)位:指示该页是否被访问过(页的置换算法)
- D(Dirty)位:指示该页是否被写过(write-back)
- NX(No Execute)位:表示该页是否可执行(64位机器)
6.4.3 页的重用
6.5 Memory Management on 64-bits Machine
我们已经学习了段式内存管理和页式内存管理。在 ICS 先导课中,我们结合32位机器(IA-32)进行了学习。在32位机器上,段页式内存管理应用非常普遍。在64位机器上,页式存储管理方案更为常见。常见的分页表结构有三种,分别是:
- 分层分页(Hierarchical Paging)
- 哈希分页表(Hashed Page Tables)
- 倒排分页表(Inverted Page Tables)
在后续的课程中,我们将探讨分层分页的页式存储管理方式,包括快表和多级页表等。
6.6 Tradeoffs
第七课 Translation Lookaside Buffer
学习页式存储管理方案中,每当CPU 访存时,访问页表会为机器带来额外的开销(两次访存)。为了减少这种开销,设计人员使用 Cache 来减少时间上的开销。现代计算机使用地址转换旁路缓冲存储器,由于合理使用TLB能够将查询页表的时间开销降低到原先的5%甚至以下,由此得名快表。
7.1 TLB
TLB 是用 SRAM 做成的一种全相联存储器(命中率高)。TLB 中存储最近使用的页表项,加快了地址的转换速度(减少访存次数)。因为是全相联存储器,所以它会将 CPU 送来的页号和 TLB 中缓存的所有页号同时比较(硬件实现复杂,成本高)。如果找到匹配条目即为命中(TLB hit)。
若命中(hit),就会直接返回匹配条目的物理地址,这种情况当然最好。根据匹配条目的位置,我们有两种不同的结局:
- 物理地址中的数据在缓存中,不需要访问内存。
- 如果物理地址中的数据块不在缓存中,则需要额外访问一次内存。
若不命中(miss),就会再查看页表,转换物理地址的同时将页表项写进 TLB。物理地址中的数据在缓存中,需要访问一次内存。
- 物理地址中的数据不在缓存中,页表命中。产生两次访存。
- 页表不命中。最差的情况,需要访问磁盘。

7.1.1 Hit Ratio
TLB 的命中率对系统性能至关重要,越高的命中率就以为这更多的地址转换可以在 TLB 中完成,减少了访存的次数(访问内存页表)。
通常情况下,TLB的命中率非常高。一般在 90% 到 99% 之间。影响的因素有多个:
- 程序的访问模式(程序的局部性原理)
- TLB 的大小和结构
要保持TLB命中率,我们还需要注意:当发生进程切换时,会使所有的 TLB 条目失效。
7.1.2 TLB的缺点
- TLB 的造价高:SRAM的全相联存储器
- TLB 的功耗高:能占到微处理器总功耗的 10% 以上
第八课 Multi-Level Page Tables
在上节课快表的学习中,我们用快表(一种cache)解决了页表所带来频繁的访存开销。在本节课中,我们学习多级页表,了解一下多级页表是如何优化页表所带来的存储开销的。
8.1 Back to Dark Ages
现如今,16GB、32GB甚至64GB的主机内存屡见不鲜。对于本节课,我们看到页表的分级可能不太理解,我们继续用 32 位 4GB 的虚存举例子。没有页表的分级结构前,我们需要 4MB 的连续内存来存储每个进程的页表。
现在的内存价格大约是 15rmb/GB,换算成 rmb/MB 更加便宜。而在1985年 Intel 386 推出时,内存的价格是骇人的 500$/MB。当时Windows 1.0 (Nov 1985) 只需要 192KB RAM 就可以运行。我们可能感觉不到那是一个多么黑暗的年代,但是我们能够感同身受的是多级页表的存在真的非常必要。当时的 i386 使用的就是二级页表。
8.2 Page Table PAGE
在 x86-32 架构下,一个进程的虚拟地址空间的理论大小为:
但是在单级页表下,即使进程不访问主存,也要为进程分配足够的页表项来覆盖整个虚拟地址空间。(连续存储)
而我们可以将页表的内存空间再进行分页,就可以把这些页表页离散的存到内存里了。这样不仅仅有助于提高内存的利用率(将大象分块放入冰箱),同时操作系统也可以实现按需分配页表空间了。刚刚单级页表中,操作系统需要为那些空洞页面也分配页表项,这太浪费空间了!当操作系统可以按需分配页表后,就可以完全不为空洞页面分配页表项,节省内存。
为了实现页表的分页,我们当然还需要额外地准备一张页目录表(Page Directory Table),用来记录页表页存放的页框号。(二级页表)
8.3 Multi-Level Page Tables
8.3.1 Two-Level Page Table
先将页表分页,本来 4MB 大小的页表可以分成 1K 页,每个页目录表(page directory/first level page table) 就只占 4KB 的空间,刚好是一个页的大小。其中每个页目录表项有 4B,记录页表页的存放的页框号,页目录表项就是 PDE(Page Directory Entry)。

每个页目录表项都对应着一个页表(page table)。我们知道,一个页表可以映射4MB的内存,那么使用二级页表就可以通过第1级页表映射第2级页表,第二级页表进一步映射有:
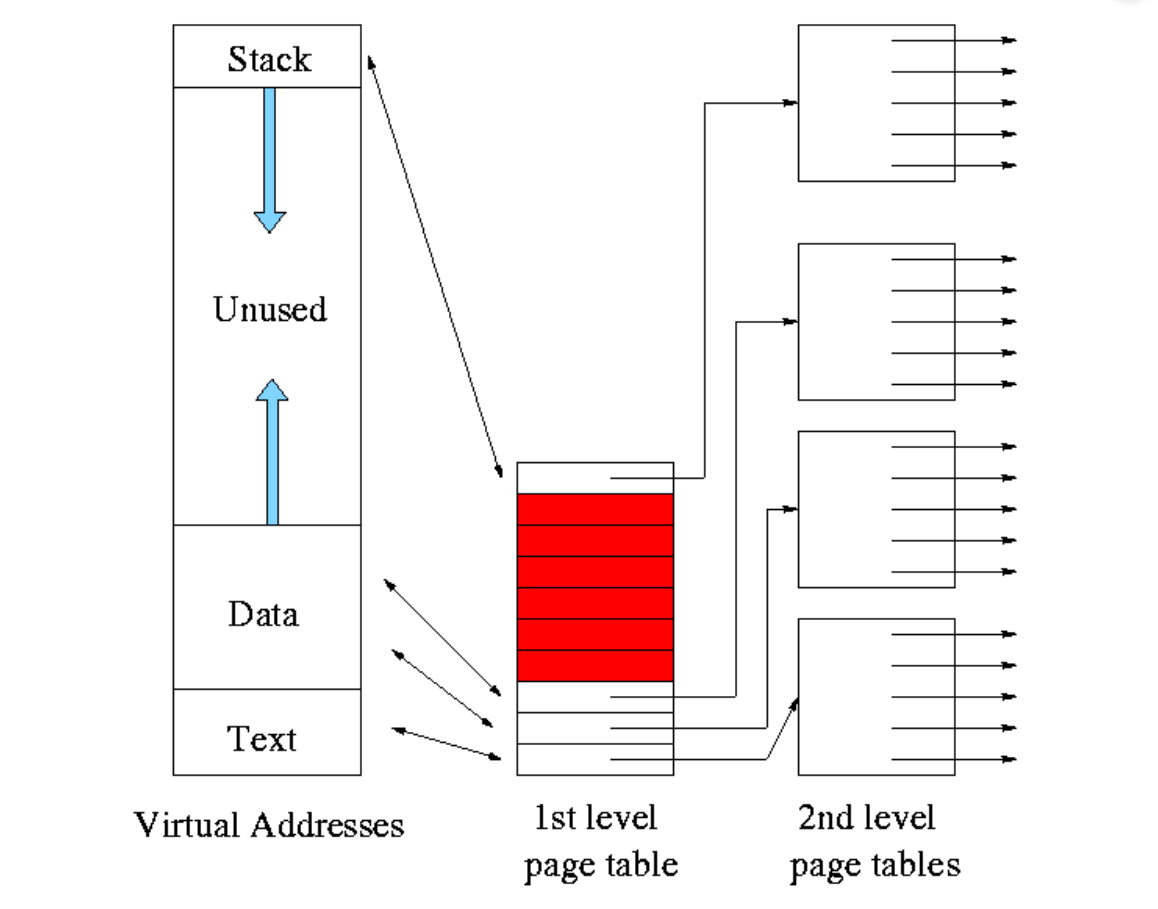
从上面的图中,我们看到页目录表的出现好像为内存增加了额外的负担,但别忘了这是操作系统不需要为空洞页面分配相应页表页的前提下的。如果进程只是用了 1GB 的虚存空间,那么用这 4KB 去换取 3MB 的页表页不载入内存好像是一个不错的交换。
8.3.2 四级页表
进入 64 位架构的时代后,进程的虚拟地址空间剧增(用户区和内核区各占256TB)。如果我们仍然使用二级页表的连续页框来存储,那么将产生:
- PGD(9bits):Page Global Directory
- PUD(9bits):Page Upper Directory
- PMD(9bits):Page Middle Directory
- PTE(9bits):Page Table Entry
- Page(12bits)
8.3.3 Tradeoffs
优点:
- 分散的页表管理
- 支持非常大的地址空间
缺点: - 地址转换时间增加(通过增加TLB优化)
- 开销增加
- 复杂性增加
第九课 Caching/Buffering
Caching是一种用于提高数据访问速度和系统性能的技术。在中学时,我们常常把正在用的书放在面前,把常用到的书摞在一起放到课桌上,不常用的书放到书包里。这就是一种cache。在我们学习快表的时候,我们知道当 TLB 命中率越高,机器的性能就越好。(因为cache常用更快的存储介质)
9.1 Locality of Reference
局部性原理,也叫引用局部性。分为时间局部性和空间局部性。局部性原理在计算机科学中的应用是非常广泛的,不仅仅应用在替换算法中。局部性原理还体现在存储器层次结构和编译器优化上。
9.1.1 Temporal Locality
时间局部性指的是,如果某个数据在被访问过一次,那么在不久的将来很可能还会被访问。当我们将这些数据放在 cache 中不进行替换,就会大大增加系统的运行性能。我们用一个例子来说明:
#include <stdio.h>
int main() {
int i, j, sum = 0;
int matrix[1000][1000];
// matirx的初始化
for(){
...
}
for (i = 0; i < 1000; i++) {
for (j = 0; j < 1000; j++) {
sum += matirx[i][j];
}
}
printf("Value of sum is: %d\n", sum);
return 0;
}
在这个例子中,变量 sum 和 j 是经常被访问的数据。将这些数据保存在缓存中可以显著提升性能,因为它们在短时间内被多次访问。。
9.1.2 Spatial Locality
空间局部性是指,当某个数据被访问到后,它周围空间之后一段时间也很有可能被访问到。继续上面的例子,如果将循环中变量 i 和 j 进行如下改动,那么空间局部性就会变得非常差。因为每次访问的地址都不是连续的,而且每一行都有1000个元素(4000字节),所以完全利用不到 cache 这个层次,总是访问主存甚至磁盘。
for (j = 0; j < 1000; j++) {
for (i = 0; i < 1000; i++) {
sum += matrix[i][j];
}
}
我们看到,尽管先按列访问的方法的作用和按行访问相同,但是由于空间的局部性,它们对 cache 利用率会大不一样,因此列访问效率会不如行访问的效率。
9.2 Memory Hierarchy
引用局部性是计算机系统中的一种可预测行为,强局部性的系统非常适合通过 cache、预取等技术进行性能优化。局部性的典型应用有层次化存储。
层次化存储是一种利用时间和空间局部性的硬件优化,可用于多个层次的内存结构中。层次化存储系统通过将存储器分为多个层次,每个层次都有不同的速度和容量,来提高内存访问效率。层次化的存储有:
- CPU寄存器:存储速度最快,速度有限(8-256个)
- L1 Cache:每个核心各有一个,容量32KB-512KB,速度很快
- L2 Cache:多个核心共享,容量128KB-24MB,速度比L1 Cache慢
- L3 Cache:所有核心共享,容量2MB-64MB,速度比L2 Cache慢
- 主存储器:容量大,但存取速度慢
- 磁盘存储:容量巨大,存取速度最慢
- 云存储:容量无限制,存取速度根据网络状况而定
根据局部性原理,现代计算机会将那些更频繁使用的数据放在高层级的存储器中。如果高层级存储器空间不够用,就会用内存置换算法将存储空间中一部分内容对换到下层次的存储器中。在替换的过程中难免会有cache数据一致性的问题,我们用替换策略和写策略来做相应应对。

9.2.1 Page Fault
缺页是指当程序访问的页面不在物理内存中时,操作系统需要从磁盘中将该页面调入内存的情况。这种情况会导致程序暂时停止执行,直到所需页面被加载到内存中。缺页特指主存到磁盘存储这一层次的页面缺失。缺页会引起中断,使操作系统介入将页面加载到内存里,由于涉及到磁盘这一层次,所以缺页非常慢,高频次的缺页可能引起性能的大幅下降。
缺页这类现象并不局限于主存-磁盘的存储结构,从Cache的结构到主存也会涉及到“缺页”相关的现象。只不过主存以下的缺页所带来的系统开销足够小,并不需要引发操作系统的重视。
9.2.2 Replacement Policy
缓存写满时,就要再写入新数据就必须选择 cache line 进行替换,此时就要考虑替换策略:
- FIFO:最早进入缓存的数据最先被替换。这种策略简单易实现,但可能不总是最优的,因为最早进入的数据不一定是最不常用的。
- LRU:最近最少使用的数据被替换。这种策略更符合局部性原理,但实现起来相对复杂,需要维护每个缓存行的使用时间戳或链表。
9.2.3 Write Policy
当一个数据再缓存中被修改了,那么对应内存数据如何处理也成了一个问题。一般情况下,我们有这两种写策略:
- Write-Through:每次写操作都同时更新缓存和主存。虽然数据一致性高,但由于每次写操作都涉及主存,速度较慢。
- Write Back:每次写操作只更新缓存,只有缓存行被替换时才写回主存。这种策略速度快,但需要额外的机制来确保数据一致性,例如脏位(Dirty Bit)来标记哪些缓存行需要写回主存。
9.3 Page Replacement Algorithms
在之前的学习中,我们了解了虚拟内存和进程的分页机制。这些机制共同作用,使系统可以加载比有限内存大得多的程序。当缺页发生(page fault),操作系统将缺失的页面加载进内存。然而这个过程是有代价的,我们这小节比较不同的算法,看看哪种算法下的hit ratio最高。
本小节我们将着重关注当主存空间满时,页面是如何置换到磁盘中,为后来加载的页面腾出空间。当CPU要访问某一页面时,如果页面在内存中就Hit,如果不在页面中就Miss。对于页面置换算法而言,命中率越高,表明性能越好,反之,性能越坏。
9.3.1 First-In, First-Out
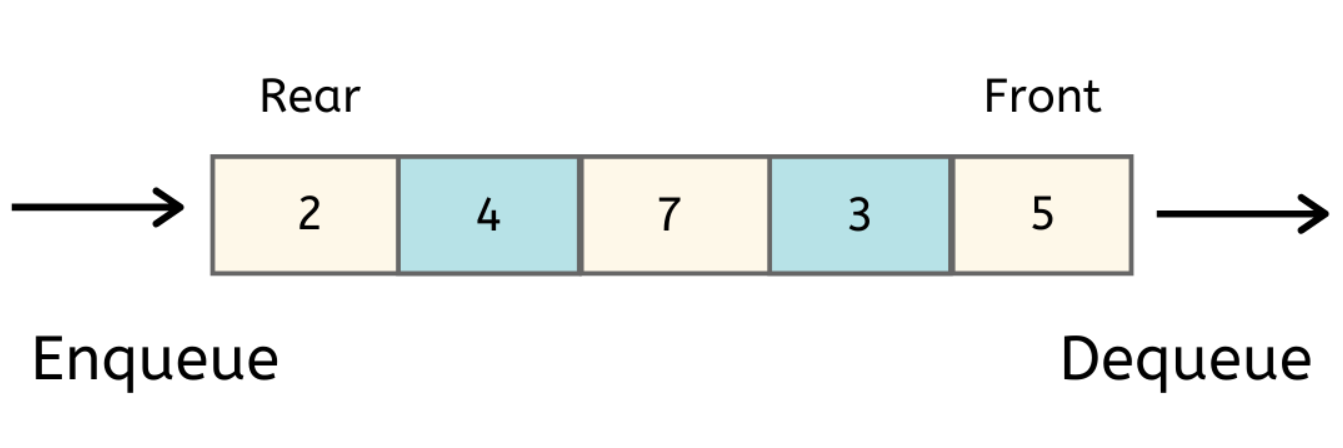
先进先出算法是简单的队列算法(Queue),队列的数据结构插入和删除发生在不同的端头,在尾部插入,在头部删除(Enqueue in rear, dequeue in front)。这种结构确保了最早进入队列的元素能够得到最早的处理,在进程调度、打印任务管理的场景得到了很好的应用。这种结构是否适用于内存的置换呢?我们最关心的是这种结构的命中率如何。我们接着看。
凡是缺页的就标记为Miss,命中的标记为Hit。如果队列满且下一次页面访存Miss,那么FIFO页面置换算法的操作系统就会选择最早进入内存的页面进行置换。我们直觉上就会感到这种算法很不靠谱,事实上也确实不靠谱。FIFO页面置换算法的命中率相比其他算法是相当低的。
而且FIFO还会引发反直觉的Bélády's Anomaly现象。主要原因是FIFO只考虑了页面的时间序列,而没有考虑页面的引用局部性。
9.3.1.1 Bélády's Anomaly
贝莱蒂现象得名于匈牙利科学家贝莱蒂发现的一种现象,即随着分配页面的增多缺页率反而增加。这是十分反直觉的,这种现象主要发生在FIFO算法中,原因我们上文也已给出。在OPT算法、LRU算法等考虑时间局部性的算法中几乎不会发生这种现象。
下面我们用一个例子直观感受一下这种现象。假设当前的队列为空,我们下面即将访问页面的顺序是:1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5。当队列中页框数为3时,我们有:

我们看到,在第一个例子中,我们总共发生了9次page faults。但是下图中,我们将队列中页框数增加到4时,我们看到,缺页次数不但没有下降,反而增加了。

“基于栈”的页面置换算法就不会受到贝莱蒂现象的影响。因为这些算法在实现时使用了类似栈的数据结构来管理页面。具体来说,这些算法维护一个页面栈,栈顶的页面是最近使用的,而栈底的页面是最久未使用的。下面我们将会学习到OPT算法和LRU算法,这两个算法都是stack-based algo。
9.3.1.2 FIFO算法优缺点
FIFO算法最大的优点就是实现简单,但是没有考虑到页面的引用局部性是FIFO最大的缺点。我们选用页面置换算法的目的是提高主存的命中率,从而减少访问磁盘的次数,使得机器的存取速度更接近主存的存取速度,进来提高机器的速度。
9.3.2 CLOCK/Second Chance Algorithm
时钟算法是FIFO的改进版,除了考虑页面的时间顺序,同时也照顾到了页面的引用情况。在之前的学习中,我们知道页表项(PTE)有一个属性位(Accessed bit),1表示访问过,0表示未访问过。CLOCK算法就是在FIFO算法的基础上为每个页面增添一个引用位(reference bit),和页表项中的accessed bit类似。
由于是FIFO算法的改进,CLOCK会按照FIFO的顺序检查每一个页面的reference位,如果reference位为1,则将此位设置为0,然后检查下一页。如果页引用位是0,就选中该页作为淘汰页。这种方式给了页第二次驻留内存的机会,因此也称为二次机会算法。
当检查完队列最后一个页面就会循环检查第一页。(Like a CLOCK spining again and again)
9.3.2.1 CLOCK+ Algorithm
CLOCK+算法是对CLOCK算法的一种改进,旨在延迟页面的置换操作。假如某个页面在加载进内存后被修改,那么它的dirty位就会置为1。我们知道,如果页面置换策略采用回写策略(write-back),则表示只有页面置换到磁盘上时才会将数据进行同步。
如果我们结合页的accessed bit和dirty bit两个属性,我们一共可以得到四种情况:
1. A = 0, D = 0 // 最先淘汰
2. A = 0, D = 1
3. A = 1, D = 0
4. A = 1, D = 1 // 最后淘汰
- 第一轮检查:
按照FIFO顺序检查1类页面,如果检出就淘汰
如果没有检出就进行第二轮检查 - 第二轮检查:
按照FIFO顺序检查2类页面,如果检出就淘汰
如果没有2类页面,则将后续页面的A位置为0
如果第二轮结束依然没有找到二类页面,则重复第一轮
9.3.3 Optimal Page Replacement Algorithm (Bélády's Algorithm)
最佳页面置换算法会选择在将来最长时间内不会访问的页面进行替换。这种算法虽然确实是一种 optimal algorithm,理论上这种算法的命中率是最高的,但是这种算法过于理想了。
因为预知未来将要访问的页面在实际的应用中几乎是不可能的。而且即使在模拟环境中实现 OPT 算法,所需要的计算资源也将是巨大的。所以 OPT 算法一般就作为 optimal algorithm 来判断一个页面置换算法的优劣。实践上,我们会用 OPT 算法与其他的算法进行比较。为其他算法提供一个理想的参考标准,用来评估其他页面置换算法的性能。
9.3.4 Least Recently Used
最近最久未使用算法算得上实际生活中页面置换算法的 GOAT ,LRU会替换最近最少使用的页面。这个根据是程序的局部性原理,即最近使用过的数据在未来一段时间后仍可能被使用。
在算法的实现中,尽管我们不能预测未来,但是我们仍然可以观察过去。我们可以通过过去访问的页来指定未来哪些页需要被先置换出去,哪些页应当保留。要实现LRU,我们需要额外地维护一个链表,用于保存刚刚访问的页面及最久未被访问的页面。且每次访问页都可能对链表排序进行调整,又是额外的时间开销。
9.3.5 Less Frequently Used
9.3.6 Not Frequently Used
9.3.7 NFU + Aging
9.3.8 ARC
第十课 Virtual Memory
10.1 Reviewing: Ideas of Virtual Memory
我们终于将虚拟内存作为单独的专题进行讨论了。我们先回顾一下为什么我们需要虚拟存储器。在早些时候,内存容量很小,所以我们需要二级存储器来作为后备力量。现在虽然我们有 16/32GB 甚至更大的主存容量,能够容纳大多数的软件,但随着软件数量的增多和体积的增大,这么大的主存容量可能还是不够用。
那么如果我们只将程序的一小部分放在主存中呢?根据程序局部性原理,我们当然可以这样做,而且带来的好处远远大于整个程序的 swapping 所带来的系统开销。先导课程中,我们介绍过早期的虚拟内存实现。当程序不再需要完全放在内存中时,这不仅节省了内存空间,还减少了每个程序使用的主存空间,同时也减少了使用 IO 进行 swapping 的次数(每次只需加载程序的一部分)。
10.1.2 Virtual Memory
虚拟内存(VM) 是操作系统管理内存的一种技术。通过将小部分的程序调入内存中运行,它可以向应用程序提供一个独享、连续且巨大的内存空间。尽管内存无法容纳所有进程,但虚拟内存提供了一种非常有效的方法来应对这种情况。即按需调入,并将长时间未访问的页调出到磁盘中。利用磁盘的大容量来运行程序。
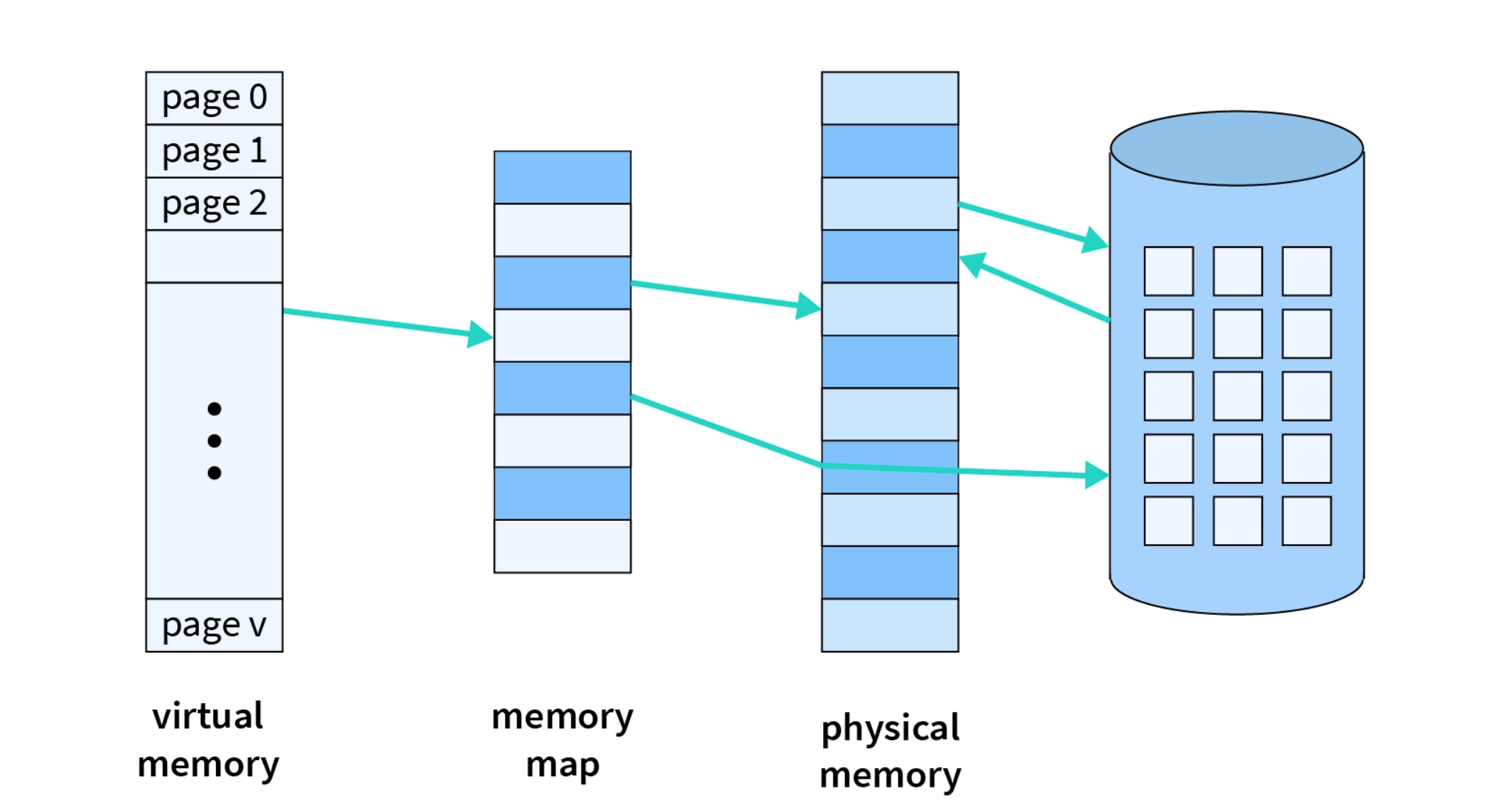
我们前面提到了页表、虚拟内存的思想blablabla,我们来总结一下虚拟内存怎么用:
- 段检查(Segmentation Check):每次CPU要访问某个内存地址的指令或数据时,内存管理单元(MMU)都会检查这个内存引用是否有效。MMU会先进行段检查,如果段不可用,就会终止程序并抛出segmentation fault。
- 缺页处理(Page Fault Handling):如果段地址有效,但引用的页不在内存中,就会发生缺页。这时操作系统会找到一个空闲页框,请求磁盘读操作(可能还会写),然后将新页面载入内存。
- 更新页表和恢复执行:当页面加载完成后,操作系统会更新页表并记录相关信息。最后,重新对该虚拟地址进行访问,继续执行程序。
10.1.3 Demand Paging
由于虚拟内存涉及到内存-磁盘这一层次的存储层次,当部分加载进内存的程序发生缺页时会发生什么呢?当进程访问的虚拟页不在物理内存中就会产生页错误。当缺页发生时,会:
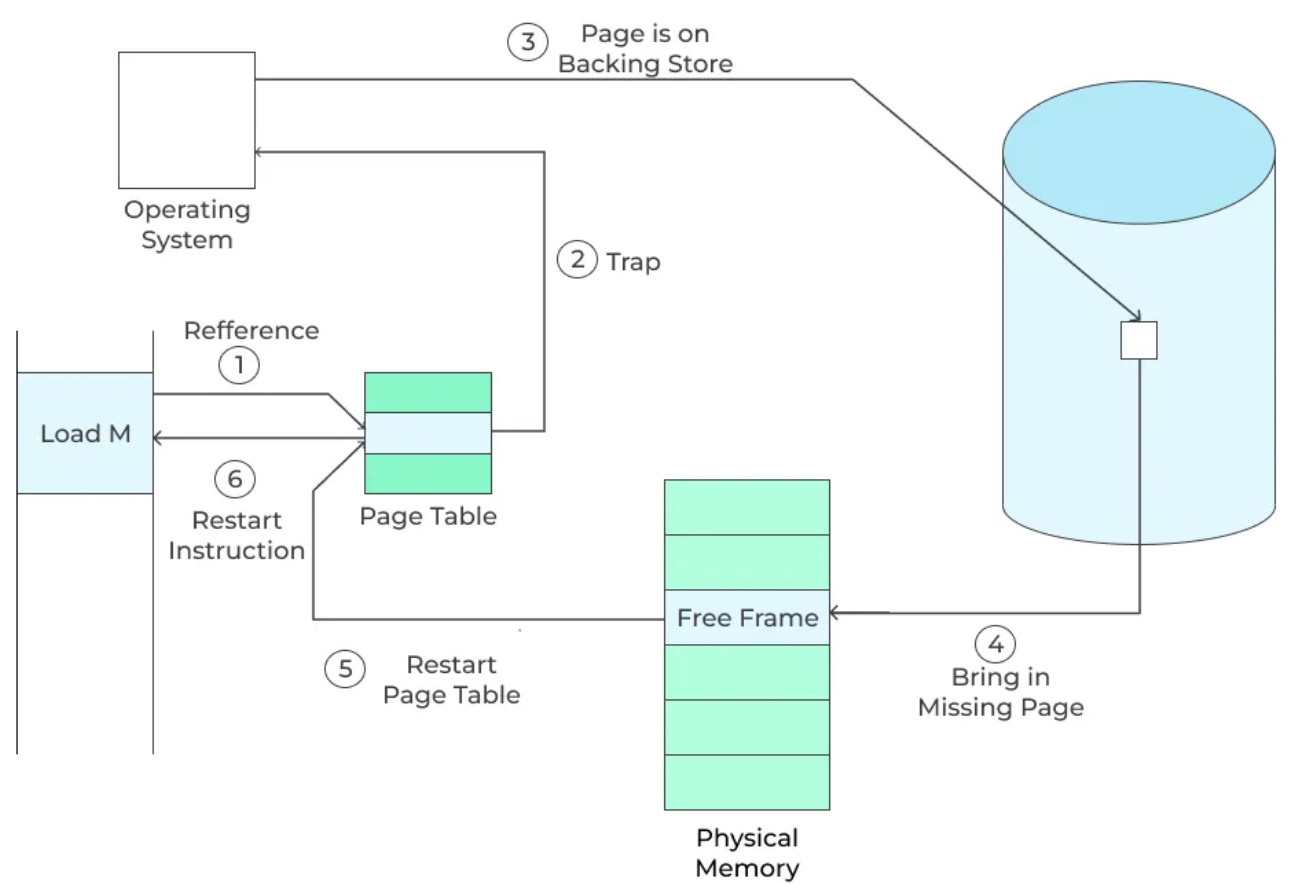
- 发生缺页,向操作系统报告。随后操作系统接管并保存运行上下文,操作系统figure out这是一个缺页中断。随后MMU检查这个地址是否合法。
- 然后就是决定加载页面到内存的某个页框中(使用页面替换算法)。在选择装入前先检查一下要替换的页面是否被修改过(脏位是否为1)。
- 如果没有修改过,跳到第 5 步。
- 如果修改过,先将该页面写回到磁盘中。磁盘写请求放在一个队列中。然后等待磁盘写执行,CPU这时会做其他的事情。当磁盘写完成之后会向操作系统发出中断信号。
- 保存寄存器和其他进程状态(为什么?)
- 发起磁盘读操作,将磁盘中的数据读到内存的空闲页框里。和前面的写操作一样,对磁盘读的请求会放在一个队列里,在磁盘读操作进行的过程中,CPU做其他的事情。
- 当磁盘完成I/O操作后,向系统发生中断信号。
- 如有必要,保存寄存器和其他进程状态。(为什么?)
- 最后更新页表,恢复执行。
10.1.3.1 Lazy Approach
:只有在需要的时候才从外存中加载到内存。(处理 page fault 就是一种 lazy approach)
10.1.3.2 HHDs and SSDs
尽管缺页需要这么多步才能恢复执行,但实际上对磁盘(HHDs)的操作是最耗费时间的。重启进程和内存的管理需要耗费 1μs - 100μs。然而,磁盘的延迟有 3ms(3000μs),寻道时间 5ms(5000μs),而传输时间只用 0.05ms(50μs)。所以,当缺页中断率很高时,性能会非常非常差。(一般而言,缺页中断率会控制在
现在,我们大多使用SSDs这种介质作为二级存储器,相比于HHDs,SSDs是一种更快、更可靠的存储解决方案。SSD的延迟通常在几十微秒(μs)范围内,远低于HHDs的毫秒(ms)级别延迟。SSD没有机械部件,因此没有寻道时间,数据传输速度也更快。这使得SSD在处理缺页中断时的性能显著优于HHDs。
10.2 Thrashing
当缺页(page fault)或换入换出(swapping)发生时,操作系统会进入内核态来处理这些事件。处理这些事件会有一定的时间开销。如果缺页的发生频率过高,CPU就不得不花费更多的时间来处理这些换出操作。这种由于换出过于频繁而导致系统性能大幅下降的现象称为抖动。
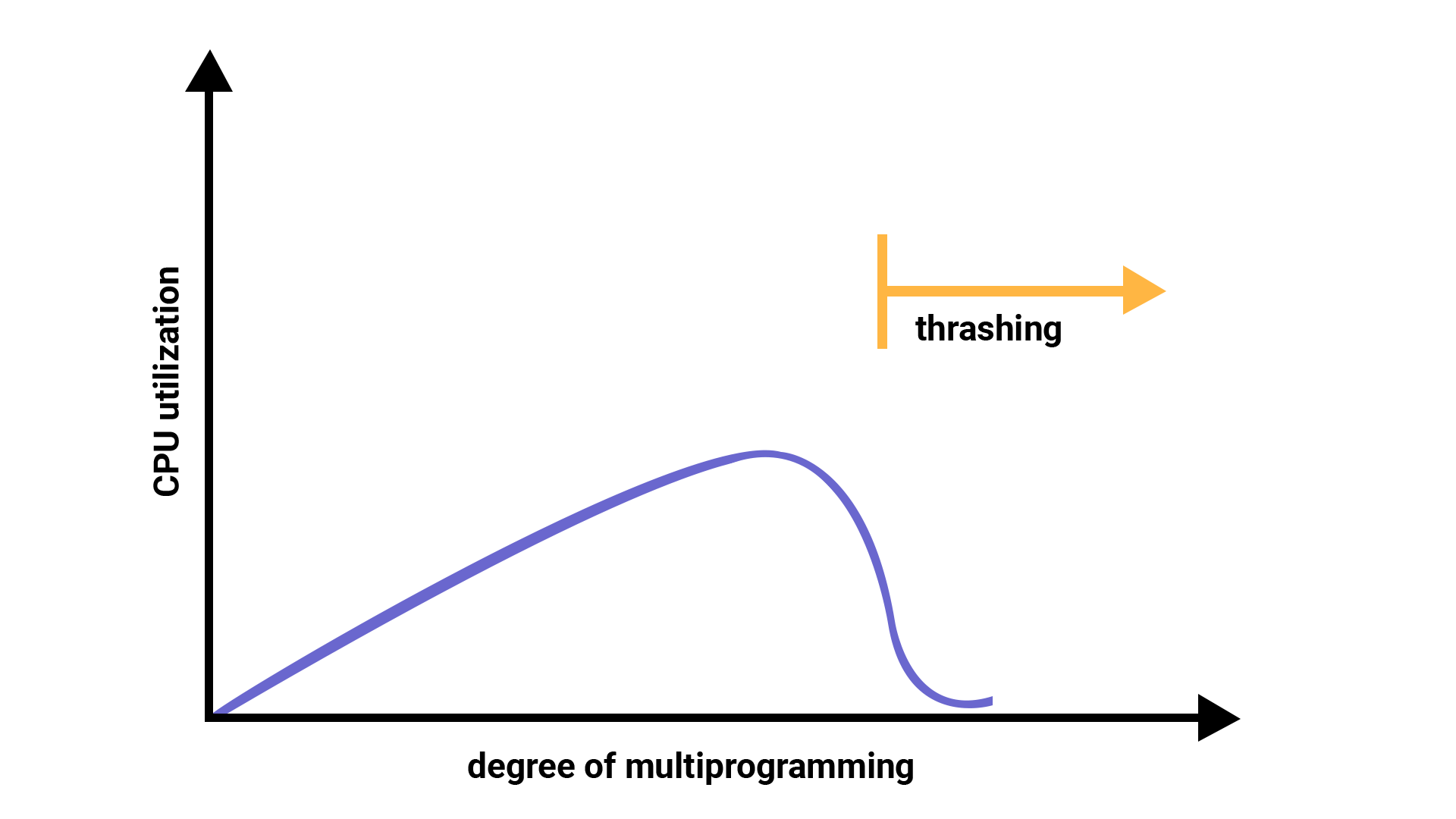
10.2.1 影响抖动的因素
引发抖动的原因可能有多个,比如并发进程数量、内存分配策略、页面调入策略、页面置换算法等。上节课我们已经了解过页面置换策略是如何影响页命中率的,下面我们着重来看内存分配策略和调页策略对抖动的影响和如何避免抖动。
10.2.2 Frame Allocation Strategies
OS为进程分配内存有两种策略,固定页框(fixed allocation) 和可变页框(variable allocation)。固定页框是指操作系统为每个进程分配一组固定数量的物理页框(物理内存块),且在进程运行期间一直保持这样数量的物理页框。固定页框策略要求每个进程只能使用自己分配的页框,不能使用其他进程的页框。等分页框(Equal Allocation) 就是一种固定页框,系统中的所有物理页框平均分配给每个进程。
可变页框是操作系统根据进程的需求动态地分配物理页框,进程运行期间,页框的数量可以增加或减少。比例分配(Proportional Allocation) 是可变页框的一种,进程分配的页框数量可以根据进程的大小和进程数量来动态调整。
固定页框实现简单,管理方便,因为每个进程的内存需求是预先确定的。但是这种分配策略的灵活性很差,可能导致内存利用率不高。如果分配的页框数量过多,会浪费内存;如果分配的页框数量过少,可能导致频繁的缺页中断。
可变页框的优缺点完全和固定页框的实现反着来,可变页框灵活性高,可以根据实际需求调整内存分配,提高内存利用率。但是实现复杂,需要更复杂的管理机制来跟踪和调整页框的分配。
10.2.3 Local and Global Page Replacement
当缺页中断发生,操作系统需要swapping需要置换的页。我们也有两种相关的实现方式:局部置换和全局置换。
局部置换是指当发生缺页中断时,操作系统只在当前进程的物理页框中选择一个页面进行置换。这样,每个进程只能使用自己分配的物理页框,不会影响其他进程的内存使用。如果某个进程的内存需求突然增加,可能会频繁发生缺页中断,影响该进程的性能。
全局置换是指当发生缺页中断时,操作系统可以在所有进程的物理页框中选择一个页面进行置换。这样,操作系统可以动态调整各个进程的物理页框数量,根据实际需求进行分配。内存利用率更高,可以更好地适应不同进程的内存需求变化。可能导致进程之间的相互干扰,一个进程的内存需求增加可能会影响其他进程的性能。
为什么固定页框和全局置换是矛盾的。
10.2.4 Paging Strategies
请页式(Demand Paging) 是当进程需要访问某个页面而页面不在内存中时,产生缺页中断,操作系统将该页面从磁盘调入内存的页面调入策略。只在需要时加载页面,减少了不必要的内存占用,但是也可能导致频繁的缺页中断,影响系统性能。
调页式(Pre-paging) 是在执行访问页面之前将之后要访问的多个页面提前加载到内存中。如果预测准确,就会减少缺页中断的频率,如果预测不准确就会加载不必要的页面,浪费内存资源。
10.2.5 Page Replacement Algorithms
除了上面的因素,页面置换算法也是影响系统发生抖动的重要因素。页面置换算法不同,缺页次数就不相同。我们熟悉的LRU就是一种好的页面置换算法。
10.3 防止抖动的策略
10.3.1 Working-Set Model
工作集模型基于局部性原理,根据局部性大致地给出程序之后最有可能访问的页有哪些。根据工作集,我们能够减少缺页的同时尽可能地节省内存页框的资源。
为确定工作集窗口,我们检测最近使用过的页,看看哪些页的使用是最频繁的,之后将工作集设置为局部时间Δ内引用最多的页面的集合(如下Δ = 10)。不难理解,如果某页面被频繁地访问,那么就会出现在工作集中。
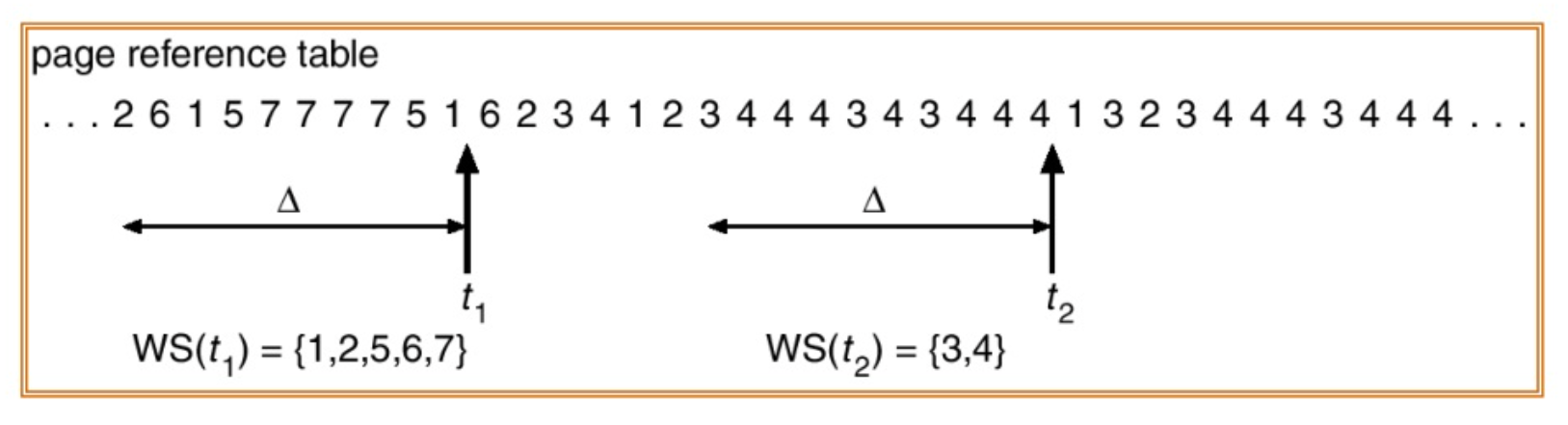
当工作集一旦被确定,系统就可以在进程启动或重启之前,根据这些历史访问数据将工作集中的页面预先调入主存(预调页的实现)。进程开始执行时就能减少缺页中断的发生,提高了系统性能。
10.3.2 Page Fault Frequency
通过之前的学习,我们了解了抖动问题的根源在于频繁的页面置换,即缺页中断频率(PFF)。如果一个进程的PFF过高,这表示系统给该进程分配的页框过少;如果系统给当前进程分配的页框非常多,就不会引起频繁的换入换出。
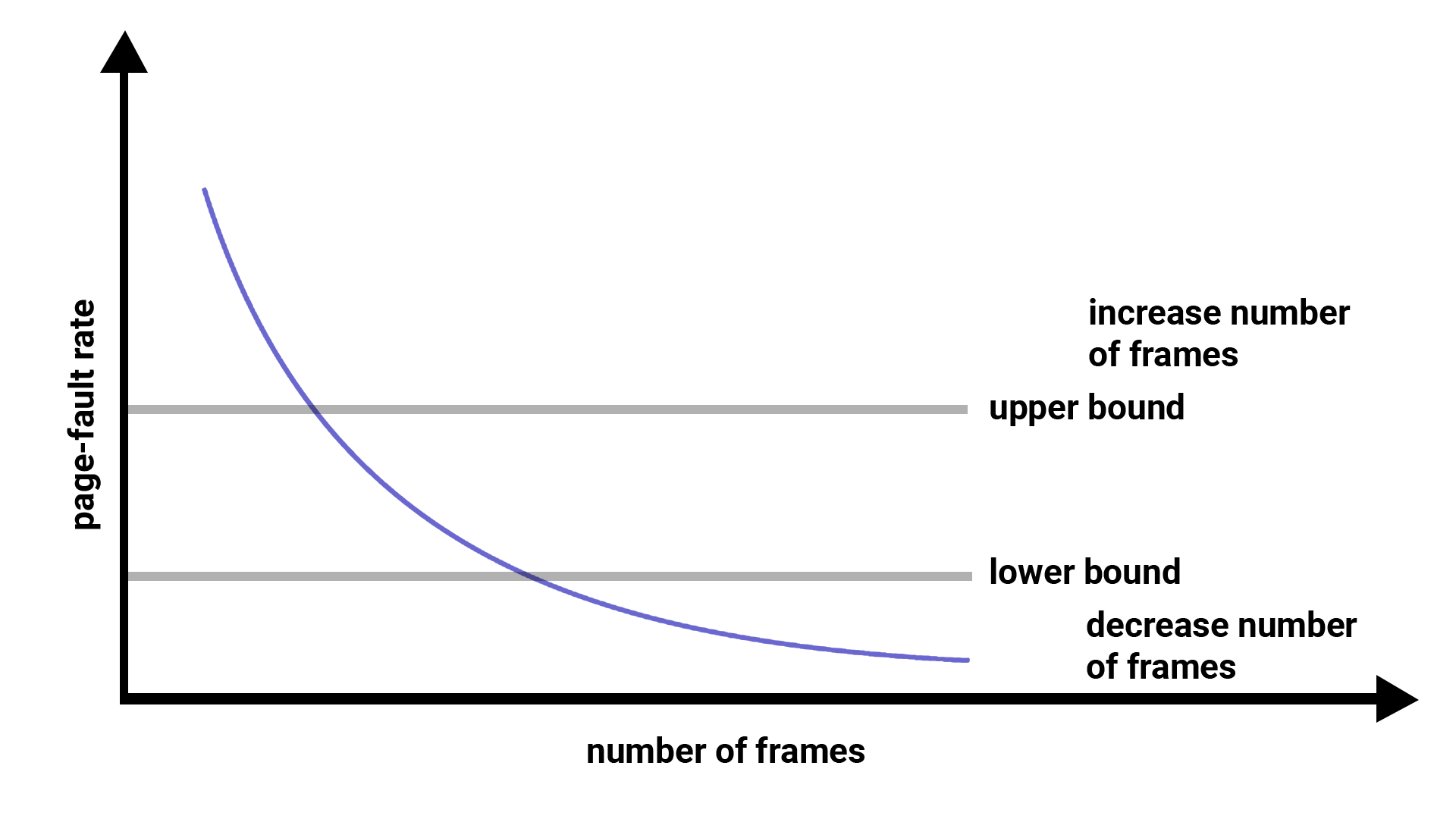
随着进程分配页框数的增加,PFF一定会减少。我们发现PFF会根据页框数呈类似于1/N的减少趋势。基于此,我们可以划定合适的上限PFF(upper bound)和下限PFF(lower bound)。根据这两个边界划分进程分配页框数。当分配的页框数过少时,PFF会显著增加(超过upper bound),从而影响性能;而当分配的页框数过多时(小于lower bound),会浪费内存页框,性价比不高。
10.x Virtual Memory Allocation
在程序中申请内存时,我们操作的是虚拟内存。操作系统负责将这些虚拟地址映射到物理内存或磁盘空间(mmap())。虚拟内存区域的分配只需确保不与现有映射冲突,无需采用物理内存管理中的best fit等算法。由于虚拟内存无需考虑碎片问题,所以通常使用更高效的方式(如 first fit )管理地址空间。
我们有两种不同的虚拟内存分配方式:静态的和动态的。
10.x.1 Static Memory Allocation
静态内存分配是在编译时分配内存的方式。程序在编译时确定变量的虚拟地址布局(如 .data 段、 .text 段等),其生命周期覆盖整个程序运行周期。物理内存的实际分配由操作系统在程序加载时完成,且内存大小不可在运行时调整。
10.x.2 Dynamic Memory Allocation
如果你需要在运行时申请内存(堆内存),你就会用到动态内存分配函数在程序运行时根据需要分配和释放内存。常见的动态内存分配函数包括 malloc 、calloc 、realloc 和 free。动态内存分配的灵活性高,可以根据程序的需要动态调整内存大小。但需要手动管理,容易发生内存泄漏。
在 Linux 系统中,malloc 库函数会在底层调用 brk(小于 128KB 的内存申请) 和 mmap 系统调用(大于 128KB 的内存申请)。(一般情况下)
10.x.2.1 brk and sbrk
它们的函数原型如下:
#include <unistd.h>
int brk(void *end_data_segment);
/*
Parameters:
1. end_data_segment: Pointer to the new end of the data segment. This value is interpreted as the new program break.
Return value: Returns 0 on success, otherwise -1 and errno is set to indicate the error.
*/
void* sbrk(intptr_t increment);
/*
Parameters:
1. increment: The amount by which to increase or decrease the program break. If the value is positive, the break is increased by increment bytes. If the value is negative, the break is decreased by increment bytes.
Return value: Returns the previous program break on success. On error, (void *) -1 is returned, and errno is set to indicate the error.
*/
10.x.2.2 mmap
mmap 我们在 IPC 章节已经介绍过,这里不在赘述。
第x课 GNU/Linux Physical Memory Map in IA32
x.1 物理内存和虚拟内存之间的映射
在本阶段,我们一直讨论有关虚拟内存怎么实现、段、页等等,但是我们的讨论仿佛一直局限在用户程序。你有没有好奇过内核在哪里存放?内核代码也需要向用户代码那样按需分配么?本节课,我们就来回顾前面阶段的知识并探讨下一些重要又有趣的细节。
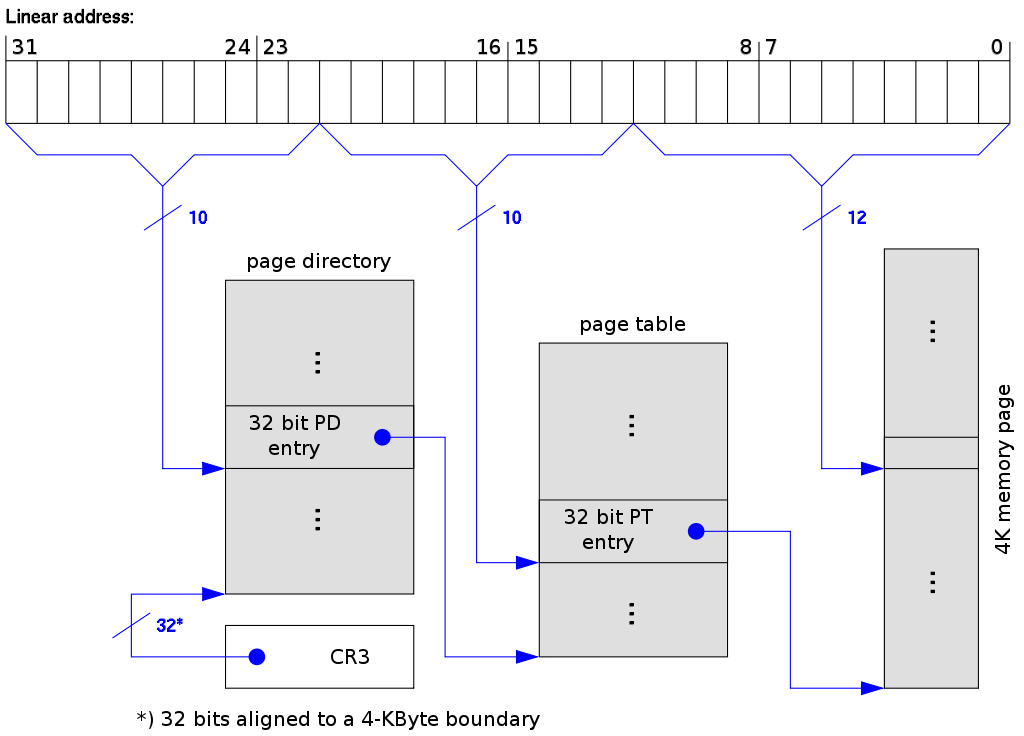
i386采用二级页表
CR3 Register用于存储页目录表的基地址。
x.1.1 实模式
0-1M
x.1.2 内核内存映射
物理地址1M往上就是内核代码和数据,再往上就是内核分配的一些数据结构,用来存放页目录或管理物理内存的结构。在往上就是空闲的物理内存。在IA32上,虚拟内存大小为4GB,其中前面的0GB-3GB我们会将其划分给用户程序,将高地址的3GB-4GB划分给内核程序。Linux将内核的1GB内存分为两部分:
- 低端地址是内核虚拟空间的低896MB,与物理内存一一映射;
- 空闲的128MB是高端内存(High memory),用来处理当物理内存大于896MB的情况。
/* This file contains the definitions for memory management in our OS. */
/* *
* Virtual memory map:
* 4G ------------------> +---------------------------------+ 0xFFFFFFFF
* | High Memory (*) | 128M
* KERNTOP -------------> +---------------------------------+ 0xF8000000
* | Remapped Physical Memory | KMEMSIZE(896M)
* | |
* KERNBASE ------------> +---------------------------------+ 0xC0000000(3G)
* | Invalid Memory (*) | --/--
* USERTOP -------------> +---------------------------------+ 0xB0000000
* | User stack |
* +---------------------------------+
* | |
* : :
* | ~~~~~~~~~~~~~~~~ |
* : :
* | |
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* | User Program & Heap |
* UTEXT ---------------> +---------------------------------+ 0x00800000
* | Invalid Memory (*) | --/--
* | - - - - - - - - - - - - - - - |
* | User STAB Data (optional) |
* USERBASE, USTAB------> +---------------------------------+ 0x00200000
* | Invalid Memory (*) | --/--
* 0 -------------------> +---------------------------------+ 0x00000000
* (*) Note: The kernel ensures that "Invalid Memory" is *never* mapped.
* "Empty Memory" is normally unmapped, but user programs may map pages
* there if desired.
*
*
* physical memory:
* 4G ------------- ---> +---------------------------------+ 0xFFFFFFFF
* | 外设映射空间 |
* | |
* 384M ----------------> +---------------------------------+ 0x20000000
* | 空闲内存~382M |
* | |
* pages end -----------> +---------------------------------+ pages end
* | npages*sizeof(struct Page) | -- (768KB)
* kpgdir end ----------> +---------------------------------+ kpgdir end
* | kern_pgdir | -- PGSIZE
* bss end -------------> +---------------------------------+ bss end
* | kernel code |
* 1M ------------------> +---------------------------------+ 0x00100000
* | BIOS ROM |
* 960KB ---------------> +---------------------------------+ 0x000F0000
* | 16位外设,扩展ROMS |
* 768KB ---------------> +---------------------------------+ 0x000C0000
* | VGA显示缓存 |
* 640KB ---------------> +---------------------------------+ 0x000A0000
* | bootloader |
* 0 ------------------> +---------------------------------+ 0x00000000
*
* */
由于是一一映射的方式,内核的虚拟地址减去KERNBASE就可以得到内核的物理地址了,方便内核对实际的内核物理内存进行管理。
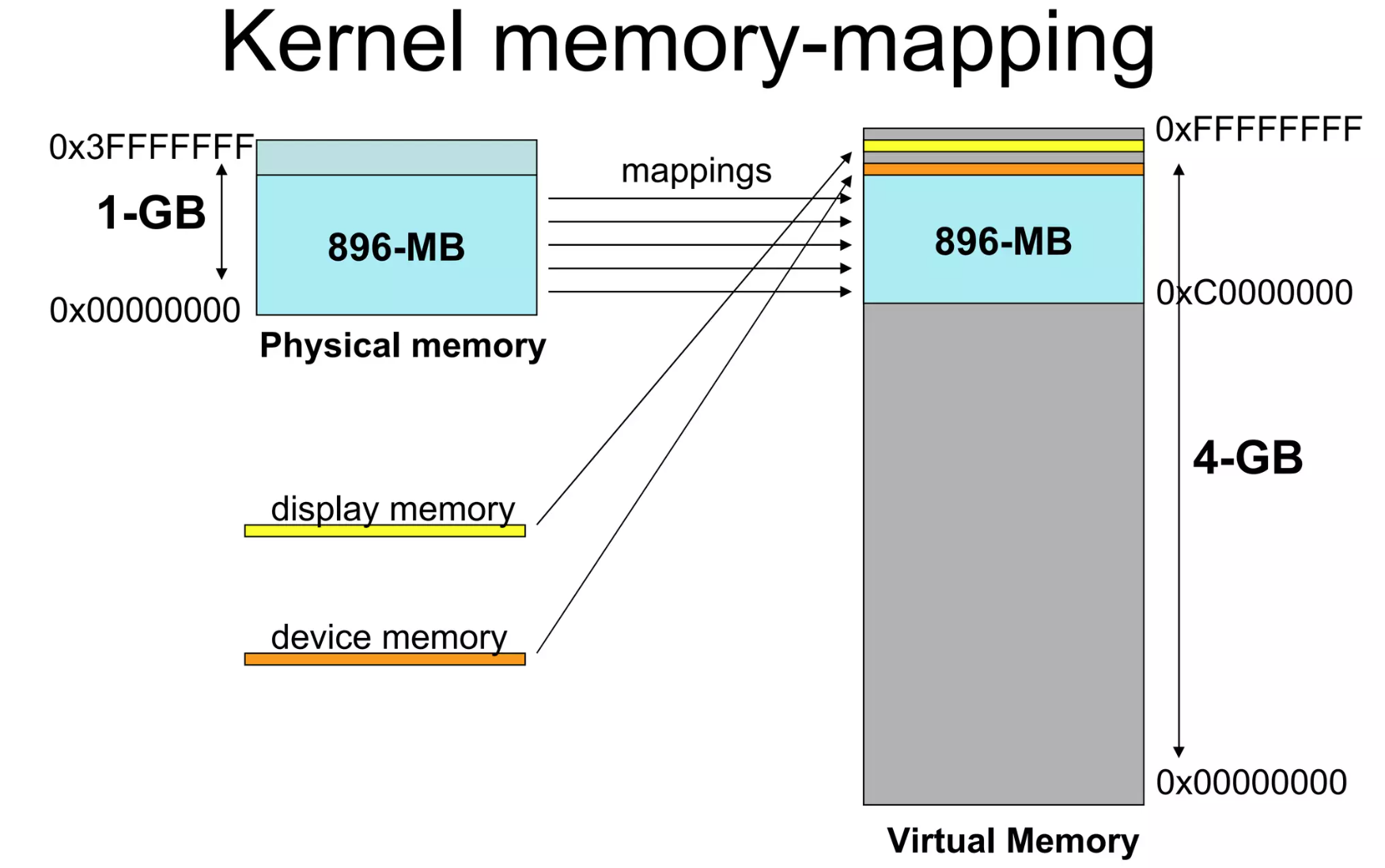
而对用户程序的地址空间会根据用户程序的情况把内存与物理内存空间进行映射。
--- 如何知道某个物理页可以释放?页结构体中有一项 uint_16t pp_ref; 表示当前页有多少个虚拟内存映射到该页代表的物理内存页。当 pp_ref 为0时就代表该页可以释放掉了。

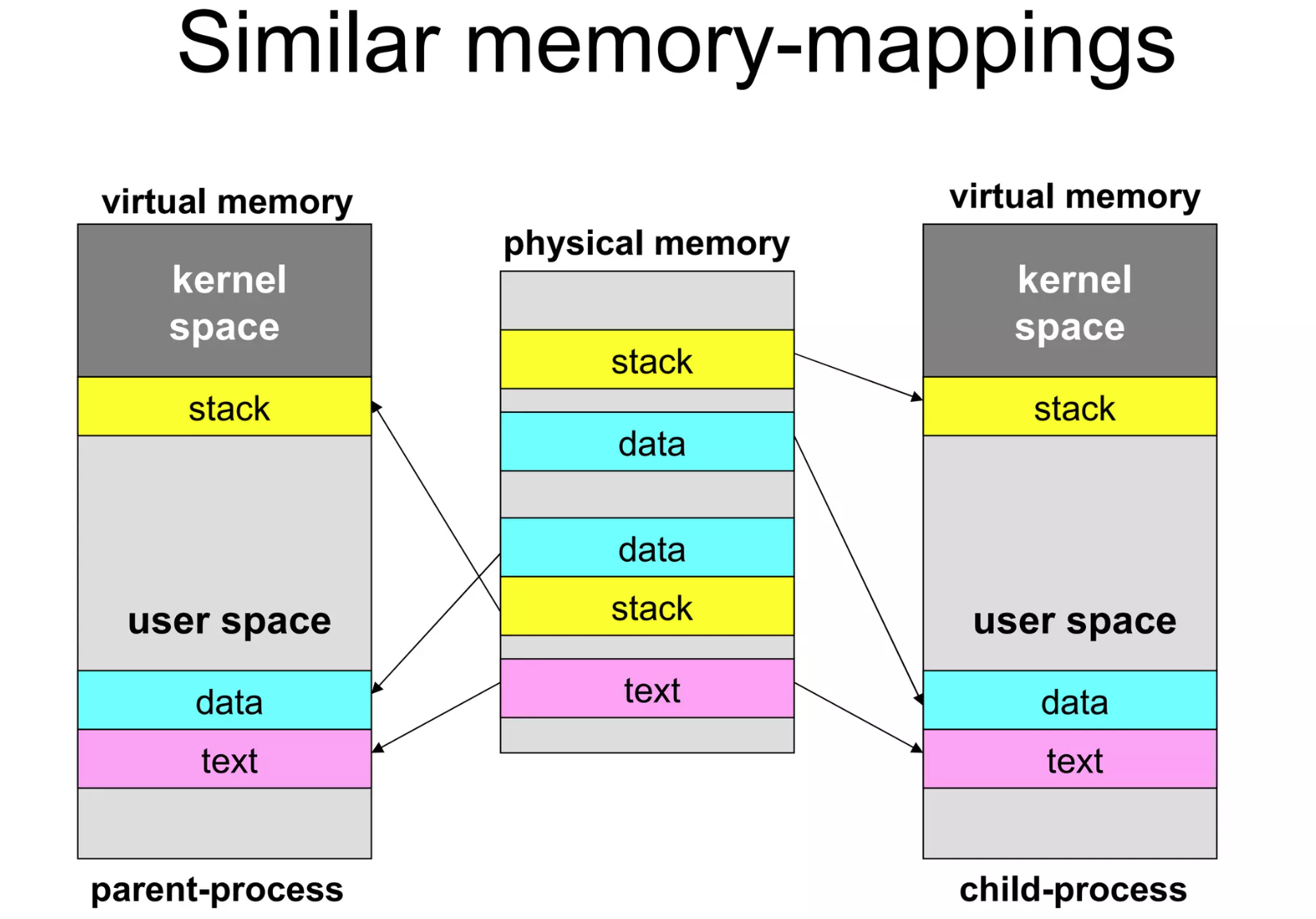
1.x mm_struct and vm_area_struct
在进程控制块 task_struct 中,我们有 mm_struct,它是一个描述进程内存管理信息的数据结构,用来管理用户进程的虚拟地址空间。mm_struct 包含了进程的地址空间信息,包括代码段、数据段、堆、栈等。它还包含了与内存管理相关的其他信息,如页表、内存映射等。
而在用户区的所有段,操作系统都会为其建立一个 vm_area_struct,存放在 mm_struct 中的 mmap 链表中,这是一个描述进程虚拟内存区域的数据结构。vm_area_struct 包含了虚拟内存区域的起始地址、结束地址、权限等信息。
对于有些数据,vm_area_struct 会和实际的物理内存建立映射。而如一次性申请 1GB 的堆内存时,操作系统只会分配一个 vm_area_struct 结构体,并不会立马与实际的物理内存建立映射关系。只有当使用时才会与物理内存建立映射关系(缺页异常并建立映射)。
此外,mm_struct 中还有一个 mmap_cache 字段,用于缓存最近访问的虚拟内存区域,以提高内存访问的效率。